In the final part of our trilogy, this article is in the form of illustrated examples.
The so-called “classical” approaches are no longer state-of-the-art, but they still form the basis of what is done today, mainly using machine learning.
Edge detection
Edge detection is the first problem that comes to mind when trying to see with a computer. To recognize an object, seeing its edges is a good first step. But, as is often the case, the initial intuition can be misleading because edge detection is a difficult problem to solve.
In fact, photos do not perfectly represent reality; they contain superfluous information (shadows, reflections) and imperfections (blur, low lighting) that sometimes make it hard to be certain of what we see.
Let’s briefly discuss a classical algorithm for detecting edges in an image: the Canny algorithm. Here is our case study, a photo of a lizard.

If we asked a human to draw the edges of this lizard, they would probably produce something like this:

Indeed, if our goal is to find a lizard in the image, this minimal representation is enough. We don’t need to see the edges of the scales or the pupil, for example. We also notice that facial features like the eyes, mouth, and nostrils are important for identifying the subject: without them, we wouldn’t recognize anything. The lizard’s dorsal crest also helps.
Yet, the Canny algorithm produces the following result:

We can recognize a lizard, but there are many superfluous edges. Moreover, some important edges have been lost because they are too dark. It would have been possible to preprocess the image to detect them, but that is not a general solution to the problem… This is the nature of a classical machine vision method: it is not automatically adaptable, nor does it “know” what is important or not. Yet, these are two crucial preconditions for vision!
Even though it is not sufficient on its own, the Canny algorithm can undoubtedly find edges. This makes it a practical tool that more advanced methods still rely on.
Corner detection
In a photo or video, the corners of objects are often points of interest (and are relatively easy to detect). For example, to stitch photos together and create a panorama, shared corners are aligned. Corners (and their movement) are also used to detect motion within a camera’s field of view, which helps, among other things, with video stabilization in post-processing.
Let’s briefly discuss a corner detection algorithm, the Harris algorithm. This photo of the Rolex Learning Center will serve as an example:

It’s a building that isn’t very angular, but we can still find “corners” there—such as the corners of the large windows. Below is the result of the Harris algorithm.

As with Canny, many superfluous corners are detected, and some are missed. Just like with Canny, a careful choice of detection parameters could eliminate the extras and find the missing ones. However, each image has its ideal parameters, and selecting them is not easy. Machine learning solves this problem by automating the search for the right parameters.
Segmentation
The third and final classical problem presented is segmentation, which is the art of dividing an image into several coherent parts.

A well-segmented image is a simple representation of the original image, without superfluous details.
Segmentation is therefore useful for all machine vision tasks: detection, classification, and tracking. This raises the question of how to do it. There are several classical methods; we’ll discuss the simplest one: thresholding.
Thresholding separates an image into two segments. Each pixel in the image is assigned to one segment or the other based on its intensity (that is, how light or dark it is). We simply compare the pixel’s intensity to a chosen threshold.
Of course, this works well on very high-contrast images, such as this one:

Once thresholded, it looks like this:

We can see that the forest is neatly grouped into the black segment, and the rest—sky and ground—into the white.
This image was very well chosen, because unfortunately, most real photos are not suited for this treatment:


Here, the rocks are not properly segmented.
That said, this technique, although very simple, is quite useful for preprocessing paper documents meant to be scanned. After all, they are often black and white, so naturally high-contrast.
OCR: reading text in images
Machine vision offers another major application: OCR, or optical character recognition. This allows reading text contained in images or videos. It powers tools like Google Lens, but it can also be found in the automatic recognition of race bib numbers in our KUVA tool.
Machine learning approaches
As we have seen, classical techniques enable computers to draw conclusions from images—in other words, to ‘see.’ But this is not without difficulties or compromises.
The most common problem, as we’ve seen, is the choice of parameters and image preprocessing. Since every image is different—with varying lighting, reflections, and transparency—each image needs to be processed differently. If our goal is to develop a system that can see under many different conditions, this problem must be solved.
And this is exactly what machine learning makes possible. ML allows the system to automatically learn the right parameters by performing many trials and errors on a test dataset that is similar to real-world situations. Easier said than done, of course, since there are also subtleties and challenges, but these are beyond the scope of this article.
Here is a rough overview of how a machine vision system based on machine learning works.
Architectures may differ, but they all share a common feature: the feature extraction phase.
Feature extraction

In practice, an input image is broken down, and the algorithm looks for specific features. Then it notes which features are present and in what quantity, and from this, it deduces what it “sees.”
In the example image, feature extraction might produce the following features:
- There are two circular objects about a quarter of the total object’s length: the wheels.
- The outline of the whole object is fairly elongated.
- Certain motorcycle parts are recognizable: handlebars, seat, bulging fuel tank.
- etc.
The algorithm’s second phase then combines these observations, and if it has been trained to recognize motorcycles, it should be able to detect one.
Feature extraction can be performed in several ways, but it often involves an exact or modified implementation of the classical techniques we’ve seen. Machine learning allows automatically tuning their parameters in the best way for the declared goal—here, detecting motorcycles—under as many conditions as possible.
Neural networks
A very popular machine learning architecture is the neural network, which comes in many different variants. Let’s imagine we want to create a neural network that detects the presence or absence of a motorcycle in an image.
The principle is simple: the system’s input is an image, in our case. The pixels of the image excite the neurons at the network’s input, in the same way our visual receptors excite our optic nerve.
Next, the central layers are affected, as all neurons are connected. But each neuron is impacted slightly differently by its predecessors. The strength of the impact is determined, for each neuron, by a parameter, a sensitivity, if you will. There is also, for each neuron, a parameter that defines how strongly it transmits its excitation to the next neurons. There can be a huge number of central layers. In our case, the first central layers will perform feature extraction, and the following layers will combine the detected features to deduce something.
Finally, the last layer contains, in our example, a single neuron. If this neuron is highly excited, it means the network has found a motorcycle; if not, it hasn’t.
The network still needs to be trained, the neurons’ sensitivities need to be adjusted so that the output is correct. And because a neural network is very flexible, there’s a good chance it can model what we’re looking for. The neurons can all be the same and perform the same calculations, or not, it’s optional.
Here, it would be wise to program the first layers of neurons to apply classical machine vision methods. We know they are probably useful for the task at hand, so rather than waiting for the network’s training to reinvent them, it’s better to integrate them.
This saves a huge amount of time and money, since training a network can be very long and energy-intensive, in addition to requiring high-end hardware.
Another improvement is possible, especially in machine vision: the CNN, or convolutional neural network.
Convolutional neural networks
A CNN is an improvement over a simple neural network because it implements feature extraction in a way that is better suited to images. Here’s an example to illustrate.
If we are looking for a motorcycle in an image, it could be on the left or the right side. Yet, this does not change the fact that it is a motorcycle. The simple neural network from earlier, however, does not perceive these two cases in the same way: for it, entirely different neurons are excited depending on the motorcycle’s position. To recognize motorcycles on the left as well as on the right, it would have to “learn” that these two cases are identical. This is not trivial and takes more training time.
The genius of the CNN is that identical stimuli, regardless of their position, naturally excite the same neurons, making it much faster to train for machine vision tasks.
This makes CNNs excellent candidates for such tasks. Below is an example diagram.
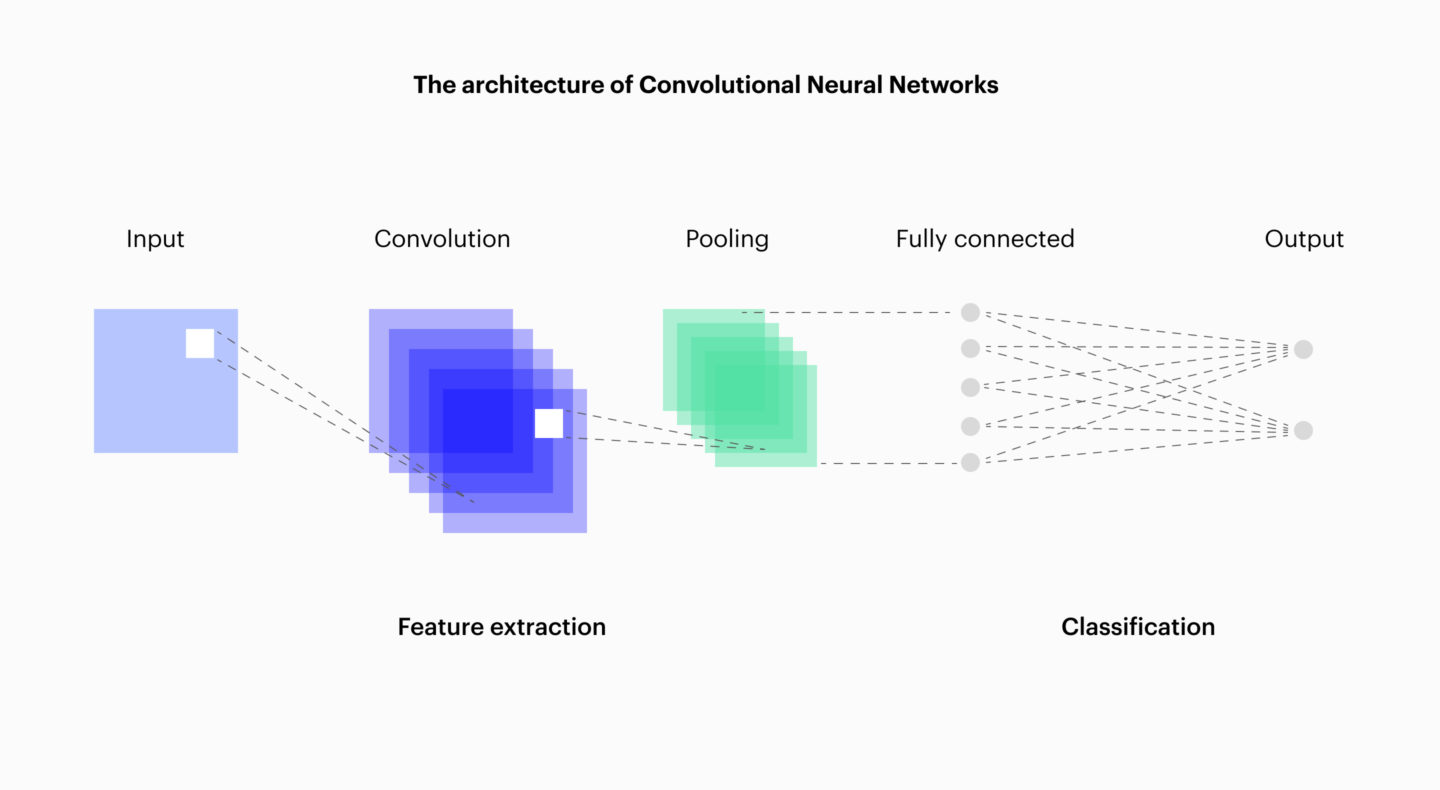
Conclusion
Machine vision is a field with its own difficulties, and it rarely (if ever) offers turnkey solutions that work in all cases. It is a fundamentally statistical domain, where certainties are always relative.
That said, it is being mastered more and more, notably thanks to advances in deep learning (which are nothing more than very large neural networks), combined with optimizations such as CNNs and the explicit programming of classical methods.
There are nevertheless many ways to fool vision systems based on machine learning. This is referred to as adversarial machine learning or dataset poisoning. As a result, we cannot rest on our laurels—there is still a great deal left to discover.



