
In our previous article, we presented computer vision from an accessible angle: how a computer “sees” an image, identifies a face, or reads a license plate. We saw why these techniques are already transforming our everyday lives.
In this article, we will delve deeper into the technical aspects of computer vision. This is aimed at those who already have some background in machine learning, image processing, or simply a strong curiosity about the technical mechanisms behind the magic.
Advanced architectures for Image recognition
CNNs: the convolution revolution
Until the early 2010s, image recognition relied on “handcrafted” descriptors: SIFT, HOG, SURF… Engineers had to explicitly code how to detect edges, textures, or colors. Then neural networks were developed and solved this problem by allowing the machine to learn how to extract relevant features without human intervention. However, these methods were still somewhat slow.
Finally, once GPUs became widely available, Convolutional Neural Networks (CNNs) truly revolutionized the field.
Their key characteristic? Enormous speed compared to previous methods. A first layer identifies simple patterns (lines, angles, textures). The following layers recombine these elements into more complex shapes (eyes, wheels, letters), while subsampling reduces resource requirements. At the very top, the dense layers make the final decision: “this is a cat,” “this is a STOP sign.”
This mechanism mirrors human perception. We recognize an animal without analyzing every pixel; CNNs imitate this process, but at a greater scale and with higher precision.
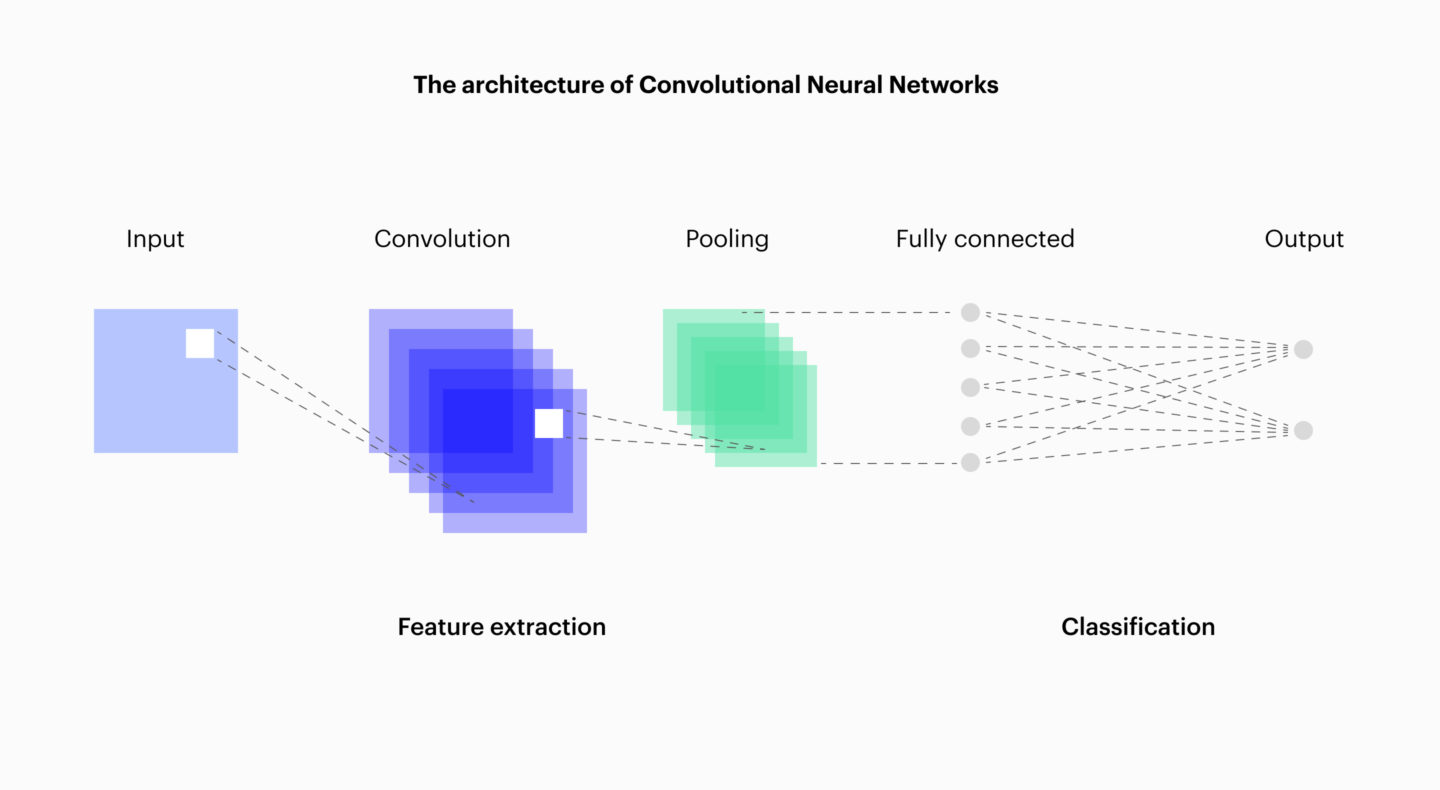
Variants and alternatives to CNNs
- ResNets: introduce “skip connections” to solve the vanishing gradient problem, making it possible to train networks with hundreds of layers (with or without convolution).
- EfficientNets: a CNN variant in which the intermediate layers are structured somewhat differently, reducing the number of hyperparameters and speeding up training.
- Vision Transformers (ViT): an alternative architecture to CNNs. They split the image into blocks and use focus to process important areas, similar to human vision.
These architectures power real-world systems: ResNet for quality control in factories, EfficientNet in medical mobile applications, and ViT for facial recognition.
Detection and segmentation: better understand the image
Here are a few more machine vision use cases that aim to enable a deeper understanding of an image.
- Object bounding: the goal is to draw a box around and label each object found in the image. Typical solutions include YOLO and Faster R-CNN, which is able to do this in real time. These solutions are used in autonomous vehicles or video surveillance.
- Semantic segmentation: each pixel is assigned a label (road, sidewalk, traffic light).
- Instance segmentation: distinguishes objects within the same category (e.g., two separate pedestrians).
These techniques go beyond a simple CNN by producing a structured understanding that can be used by navigation software, medical tools, or industrial systems.
Data preprocessing and augmentation
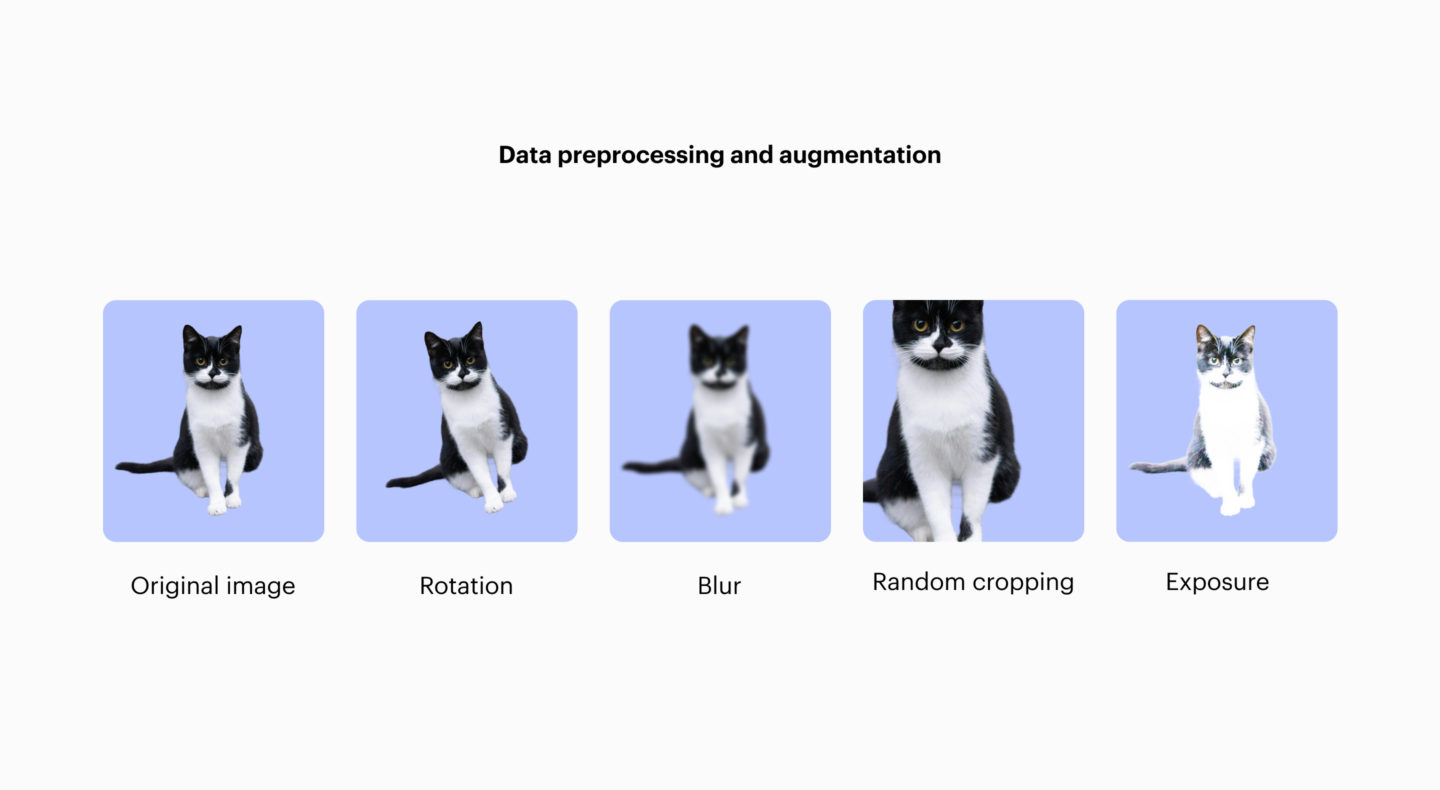
Augmentation: teaching flexibility
Humans can recognize a cat in different positions and lighting. For a machine, however, it is not automatic to understand that the same subject can appear in many different ways. That’s why we expand our training set with more or less artificial variations of the original images: rotations, cropping, changes in brightness or color, and so on.
It’s interesting to note that a CNN automatically handles translations without extra work! This is one of the reasons for its widespread adoption.
Normalization: putting images on equal footing
Raw images vary depending on shooting conditions, lighting, or color. Normalization recenters the values around 0 and adjusts the standard deviation. This makes all images more similar to each other and stabilizes the learning process.
Fighting overfitting
Overfitting is a problem: the computer memorizes everything exactly and then struggles when faced with a new image or one slightly different from what it knows. To combat overfitting, so-called regularization techniques are used, such as dropout and batch normalization.
Supervised, semi-supervised, and self-supervised learning
Machine learning can be divided into three categories:
- Supervised: networks trained on images annotated by humans.
- Semi-supervised: the training set contains a small number of annotated images along with a large volume of unannotated ones.
- Self-supervised and contrastive learning: the machine learns to distinguish images from each other without direct human supervision.
Measuring performance: beyond raw accuracy
Several metrics are used. Here are a few:
- Accuracy: the proportion of predictions made that are correct.
- Recall: the proportion of theoretically correct predictions that were actually made.
- F-score: high accuracy can hurt recall and vice versa, but we want both. The F-score provides a measure of this balance.
- Intersection over Union (IoU): for algorithms that box or segment objects, IoU measures the quality of the bounding. If a box is too big or too small, it’s useless.
In some fields, even a small difference in metrics can have significant consequences (e.g., healthcare).
Specialized applications
Medicine
Detecting a tumor on a CT scan or monitoring the progression of a disease via MRI.
Autonomous vehicles
Detecting pedestrians, signs, and obstacles. Robustness and speed are crucial in this domain.
Video analysis (sports, security, etc.)
Automatic tracking of players, detection of unusual behavior, and analysis of customer flow in stores.
Current challenges and research
Even though progress is impressive, computer vision faces several challenges:
- Robustness: a model that performs well in the lab can fail under real-world conditions (rain, fog, variations in lighting).
- Explainability: understanding why an AI “sees” one thing or another remains difficult.
- Bias and ethics: how can these technologies be used without harming individual rights? How can we avoid amplifying biases present in the data?
These issues are at the heart of current research and will shape how computer vision is adopted in everyday life.
Conclusion
Computer vision has evolved from manually parameterized descriptors to deep neural networks and transformers. Every application, from medical diagnosis to autonomous vehicles, relies on intensive research and engineering—it is not automatic.
The field exemplifies the meeting of scientific rigor and human inventiveness. For those who want to understand how a machine learns to see, it is a demanding and fascinating territory



