
Dans notre précédent article, nous avons présenté la vision par ordinateur sous un angle accessible : comment un ordinateur “voit” une image, identifie un visage ou lit une plaque d’immatriculation. Nous avons vu pourquoi ces techniques transforment déjà notre quotidien.
Dans cet article, nous allons approfondir les aspects techniques de la computer vision. Il s’adresse à ceux qui ont déjà quelques notions en machine learning, en traitement d’images ou simplement une curiosité plus poussée pour les rouages techniques derrière la magie.
Architectures avancées pour la reconnaissance d’images
Les CNN : la révolution de la convolution
Jusqu’au début des années 2010, la reconnaissance d’images reposait sur des descripteurs “faits main” : SIFT, HOG, SURF… Les ingénieurs devaient coder explicitement comment détecter des bords, textures ou couleurs. Puis, les réseaux neuronaux furent développés et résolurent ce problème en permettant à la machine d’apprendre à extraire des caractéristiques pertinentes sans intervention humaine. Ces méthodes étaient encore un peu lentes cependant.
Finalement, une fois que les GPUs se sont démocratisés, les Convolutional Neural Networks (CNN) ont réellement bouleversé la discipline.
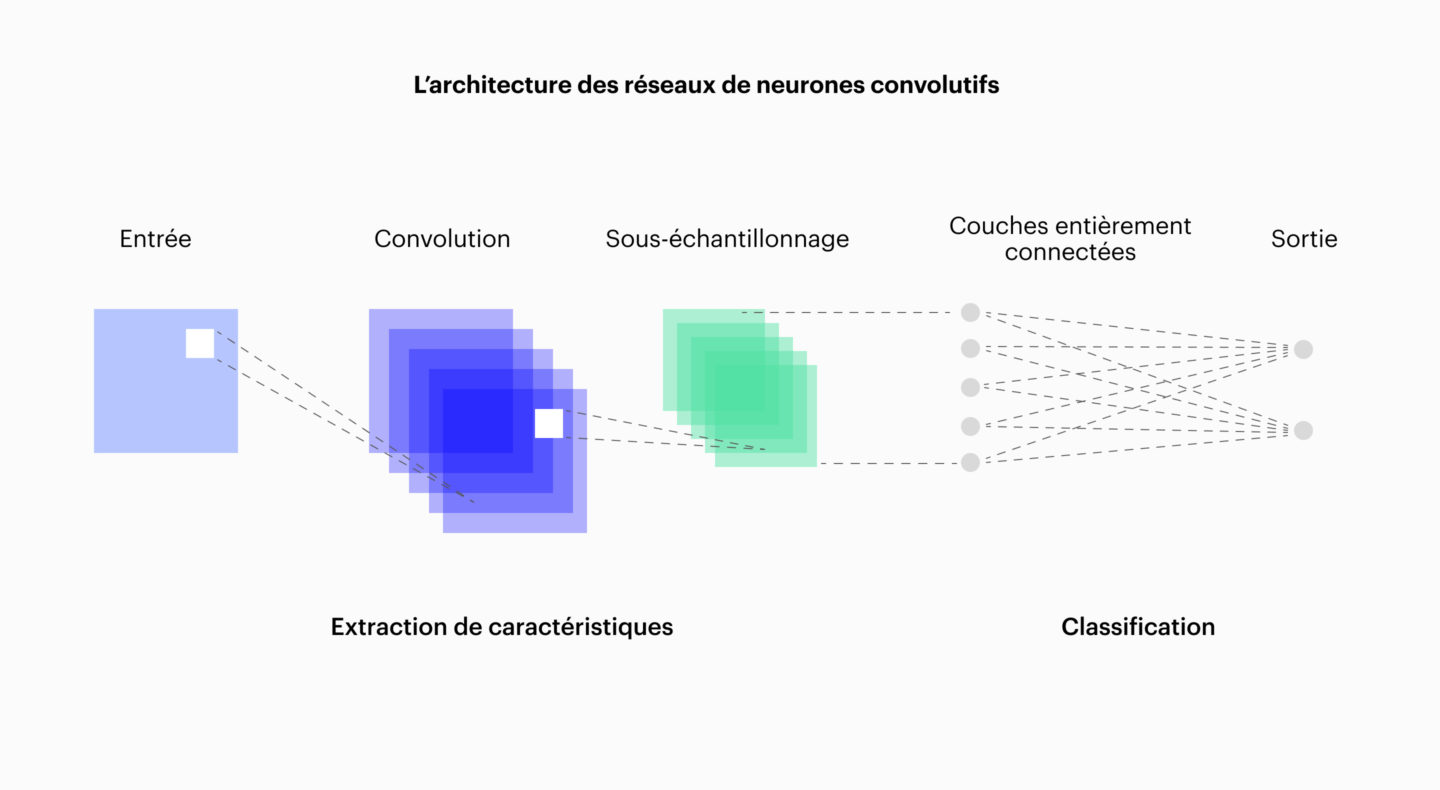
Leur caractéristique ? Une rapidité énorme par rapport aux précédentes méthodes. Une première couche identifie des motifs simples (lignes, angles, textures). Les suivantes recombinent ces éléments en formes plus complexes (yeux, roues, lettres), alors qu’un sous-échantillonnage réduit les besoins de ressources. Tout au sommet, les couches denses prennent la décision finale : “c’est un chat”, “c’est un panneau STOP”.
Ce mécanisme rappelle notre perception humaine. Nous reconnaissons un animal sans analyser chaque pixel ; les CNN imitent ce processus, mais à une échelle et précision supérieures.
Variantes et alternatives aux CNN
- Les ResNet : introduisent les “skip connections” pour résoudre le problème du vanishing gradient, ce qui permet d’entraîner des réseaux de centaines de couches (avec ou sans convolution).
- Les EfficientNet : variante des CNN dont les couches intermédiaires sont structurées un peu différemment, ce qui permet de réduire le nombre d’hyperparamètres et accélérer l’entraînement.
- Les Vision Transformers (ViT) : une architecture alternative au CNN. Ils découpent l’image en blocs et utilisent l’attention pour traiter les zones importantes, comme notre regard humain.
Ces architectures alimentent des systèmes concrets : ResNet pour le contrôle qualité en usine, EfficientNet dans des applications mobiles médicales, ViT pour la reconnaissance faciale.
Détection et segmentation : mieux comprendre l’image
Voici encore quelques cas de figures de machine vision qui visent à permettre une compréhension plus profonde de l’image.
- Encadrement d’objets : l’objectif est d’entourer et de nommer chaque objet trouvé dans l’image. Les solutions typiques sont YOLO et Faster R-CNN, qui peuvent le faire en temps réel. Ces solutions sont utilisées dans les véhicules autonomes ou la vidéosurveillance.
- Segmentation sémantique : chaque pixel reçoit une étiquette (route, trottoir, feu).
- Instance segmentation : distingue les objets d’une même catégorie (ex. deux piétons distincts).
Ces techniques vont plus loin qu’un simple CNN, en produisant une compréhension structurée exploitable par un logiciel de navigation, un outil médical ou un système industriel.
Prétraitement et augmentation des données
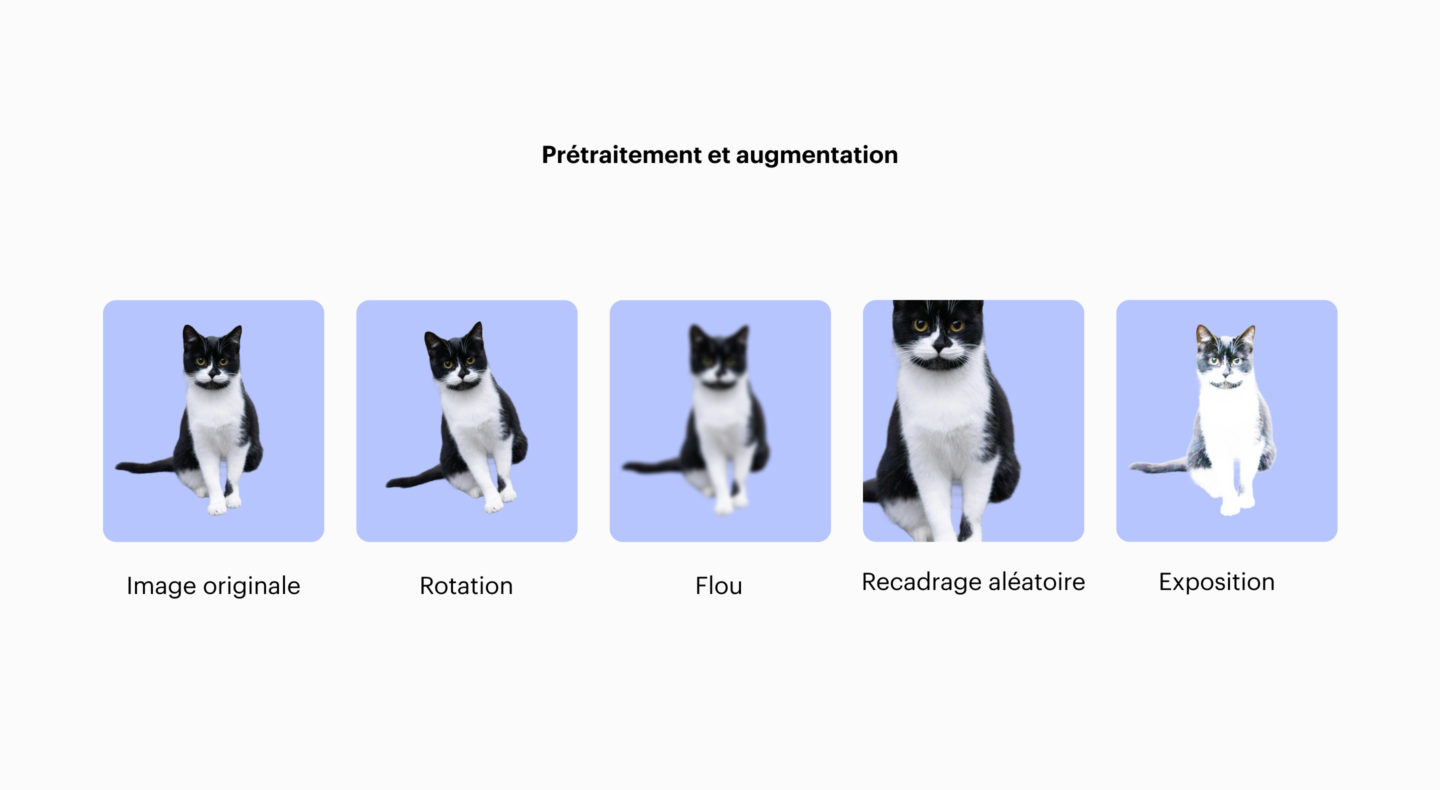
Augmentation : enseigner la flexibilité
L’humain reconnaît un chat sous différentes positions et lumières. Or, pour la machine, ce n’est pas automatique de comprendre que le même sujet peut apparaître de mille façons. C’est pourquoi on va agrandir notre training set avec plus ou moins de variations artificielles de nos images originales : rotations, recadrages, changements de luminosité ou couleur, etc.
Il est intéressant de savoir qu’un CNN comprend automatiquement les translations sans travail supplémentaire ! C’est une des raisons de sa large adoption.
Normalisation : des images sur un pied d’égalité
Les images brutes varient selon les conditions de prise de vue, lumineuses ou non, colorées ou non. La normalisation recentre les valeurs autour de 0, ajuste l’écart-type. Ainsi, toutes les images sont plus similaires entre elles et l’apprentissage est plus stable.
Lutter contre le surapprentissage
L’overfitting est un problème : l’ordinateur apprend tout exactement par cœur et donc se retrouve perdu devant une image nouvelle ou un peu différente de ce qu’il connaît. Pour combattre l’overfitting, on utilise des techniques dites de régularisation : le dropout, la batch normalization.
Apprentissage supervisé, semi-supervisé et auto-supervisé
On sépare l’apprentissage machine en 3 catégories :
- Supervisé : réseaux entraînés sur des images annotées par des humains.
- Semi-supervisé : le training set contient un petit nombre d’images annotées avec un grand volume non annoté.
- Auto-supervisé et contrastive learning : la machine apprend à distinguer les images entre elles, sans supervision humaine directe.
Mesurer la performance : au-delà de la précision brute
On utilise plusieurs métriques. En voici quelques unes :
- Précision : proportion des prédictions faites qui sont correctes. (Ne pas dire n’importe quoi.)
- Recall (rappel) : proportion des prédictions théoriquement correctes qui ont bien été faites. (Ne rien oublier.)
- F-score : une excellente précision peut nuire au rappel et vice-versa, mais nous voulons les deux. Le F-score donne une mesure de cet équilibre.
- Intersection over Union (IoU) : pour les algorithmes qui entourent ou segmentent des objets, l’IoU est une mesure de qualité de l’encadrement. Si un cadre est trop grand ou trop petit, il est inutile.
Dans certains domaines, même une petite différence de métrique peut avoir des conséquences importantes (ex. santé).
Applications spécialisées
Médecine
Détecter une tumeur sur un scanner ou suivre l’évolution d’une maladie sur une IRM.
Véhicules autonomes
Détecter piétons, panneaux, obstacles. La robustesse et la rapidité sont cruciales dans ce domaine.
Analyse vidéo (sport, sécurité…)
Suivi automatique des joueurs, détection de comportements inhabituels, étude du flux de clients en magasin.
Défis actuels et recherches
Même si les progrès sont impressionnants, la vision par ordinateur fait face à plusieurs défis :
- Robustesse : un modèle performant en laboratoire peut échouer dans des conditions réelles (pluie, brouillard, variations de lumière).
- Explicabilité : comprendre pourquoi une IA voit telle ou telle chose reste difficile.
- Biais et éthique : comment utiliser ces technologies sans nuire aux droits des individus ? Comment éviter d’amplifier les biais présents dans les données ?
Ces enjeux sont au cœur de la recherche actuelle et conditionnent la manière dont la vision artificielle sera adoptée dans notre quotidien.
Conclusion
La vision par ordinateur est passée des descripteurs à paramétrer manuellement, aux réseaux neuronaux profonds et aux transformers. Chaque application, du diagnostic médical aux voitures autonomes, repose sur une recherche et ingénierie poussées, et n’est pas automatique.
Le domaine illustre la rencontre entre rigueur scientifique et inventivité humaine. Pour ceux qui veulent comprendre comment la machine apprend à voir, c’est un terrain exigeant et passionnant.



