Dernier volet de notre triptyque, nous vous proposons ici un article sous forme d’exemple illustré.
Les approches dites “classiques” ne représentent plus le SOTA mais sont encore la base de ce qui se fait aujourd’hui plutôt avec du machine learning.
Edge detection
La détection des contours est le premier problème qui vient à l’esprit quand on souhaite voir par ordinateur. Pour voir un objet, voir ses contours est un bon premier pas. Mais, la première intuition, comme souvent, est trompeuse, car l’edge detection est un problème difficile à résoudre.
En fait, les photographies ne représentent pas parfaitement la réalité, elles contiennent des informations superflues (ombres, reflets) et des imperfections (flous, manques de luminosité) qui empêchent parfois d’être sûr de ce qu’on voit.
Parlons brièvement d’un algorithme classique pour détecter les bords dans une image, l’algorithme de Canny. Voici notre cas d’étude, une photo de lézard.

Si on demandait à un humain de dessiner les contours de ce lézard, il ferait probablement quelque chose comme ceci :

Effectivement, si notre but est de trouver un lézard dans l’image, cette représentation minimale suffit. On n’a pas besoin de voir les contours des écailles, ou de la pupille par exemple. On remarque aussi que les caractéristiques faciales comme les yeux, la bouche et les narines sont importantes pour identifier un sujet : sans eux, on ne reconnaîtrait pas quoi que ce soit. La crête dorsale du lézard aide également.
Pourtant, l’algorithme de Canny produit le résultat suivant :

On peut reconnaître un lézard, mais il y a beaucoup de contours superflus. De plus, des contours importants ont aussi été perdus car trop sombres. Il aurait été possible de prétraiter l’image pour les faire détecter, mais ce n’est pas une solution générale au problème… C’est le propre d’une méthode classique de machine vision : elle n’est pas automatiquement adaptable, ni a-t-elle conscience de ce qui est important ou non. Pourtant, ce sont là deux préconditions importantes à la vision !
Quand bien même il ne se suffit pas à lui-même, l’algorithme de Canny peut sans aucun doute trouver des contours. Cela en fait un outil pratique auquel les méthodes plus avancées font appel.
Corner detection
Dans une photo ou une vidéo, les coins des objets sont souvent des points d’intérêt (ils sont assez faciles à détecter). Par exemple, pour coudre des photos les unes aux autres et créer un panorama, on va aligner les coins partagés. On utilise aussi les coins (et leur déplacement) pour détecter le mouvement dans l’espace d’une caméra, ce qui permet entre autres la stabilisation d’une vidéo en post-processing.
Parlons brièvement d’un algorithme de corner detection, l’algorithme de Harris. Cette photo du Rolex Learning Center servira d’exemple :

C’est un bâtiment qui n’est pas très anguleux, mais on peut quand même y trouver des “coins”. Ceux des baies vitrées par exemple. Ci-dessous se trouve le résultat de l’algorithme de Harris.

On voit que, comme pour Canny, beaucoup de coins superflus ont été trouvés. D’autres ont été ignorés. Comme pour Canny, un choix savant des paramètres de détection auraient permis d’éliminer les superflus et de trouver les manquants. Cependant, chaque image a ses paramètres idéaux, et leur choix n’est pas facile. Le machine learning permet de résoudre ce problème en automatisant la recherche des bons paramètres.
Segmentation
Le troisième et dernier problème classique présenté est la segmentation, c’est-à-dire l’art de découper une image en plusieurs morceaux cohérents.

Une image bien segmentée est une représentation simple et sans détails superflus de l’image originale.
La segmentation aide donc pour tous les buts de la machine vision : détection, classification, tracking. Vient alors la question de savoir comment faire. Il y a plusieurs méthodes classiques, et nous parlons ici de la plus simple, le thresholding.
Le thresholding permet de séparer une image en 2 segments. Chaque pixel de l’image est attribué à un segment ou l’autre selon l’intensité du pixel (c’est-à-dire à quel point il est clair ou foncé). On compare simplement l’intensité du pixel à un seuil que l’on choisit. (Seuil = threshold en anglais, d’où le nom).
Évidemment, cela fonctionne bien sur les images très contrastées comme par exemple celle-ci :

Qui une fois thresholdée donne ceci :

On voit que la forêt est assez bien rangée dans le segment noir, et le reste, ciel et terre, dans le blanc.
Cette image était très bien choisie, car malheureusement, la plupart des photos réelles ne sont pas adaptées à ce traitement :


Ici, les pierres ne sont pas correctement segmentées.
Cela dit, cette technique, bien que très simple, est assez utile pour prétraiter des documents papiers destinées à être scannés. Ils sont après tout souvent noirs et blancs, donc naturellement contrastés.
OCR : lire le texte dans les images
La machine vision offre une autre grande application qui est l’OCR : reconnaissance optique de caractères. Cela permet de lire du texte contenu dans des images ou vidéos. C’est ce qui propulse Google Lens par exemple, mais on peut aussi la trouver dans la reconnaissance automatique de numéros de dossards de notre outil KUVA.
Approches machine learning
Comme on l’a vu, les techniques classiques permettent de soutirer des conclusions depuis des images, donc à voir. Mais si elles permettent à l’ordinateur de voir, ce n’est pas sans difficultés ni compromis.
Le problème le plus courant, on l’a vu, c’est celui du choix des paramètres et du prétraitement de l’image. Comme toute image est différente, avec une lumière, des reflets, des transparences différentes, il faut traiter chaque image différemment. Si notre objectif est de développer un système qui peut voir dans beaucoup de conditions différentes, il faut résoudre ce problème.
Et c’est justement ce que le machine learning va permettre de faire. Le ML permet d’apprendre automatiquement les bons paramètres en faisant beaucoup d’essais et d’erreurs sur un dataset de test qui est similaire aux situations réelles. C’est plus facile à dire qu’à faire, car il y a là aussi des subtilités et des difficultés, mais elles ne sont pas le sujet de cet article.
Voici comment fonctionne grossièrement un système de machine vision fondé sur du machine learning.
Les architectures diffèrent, mais leur point commun est la phase d’extraction des caractéristiques (feature extraction en anglais).
Feature extraction

Concrètement, une image d’entrée va être décortiquée, et l’algorithme va y chercher des caractéristiques particulières. Ensuite, il constate quelle caractéristique est présente en quelle quantité, et il en déduit ce qu’il voit.
Sur l’image d’exemple, l’extraction pourra produire les caractéristiques suivants :
- Il y a deux objets circulaires d’un diamètre d’environ un quart de la longueur de l’objet total : les roues.
- Le contour de l’objet total est assez élancé.
- On reconnaît certaines pièces de moto : guidon, siège, réservoir bossu.
- etc.
La deuxième phase de l’algorithme combine ensuite ses observations, et s’il a été entraîné à reconnaître les motos, il devrait pouvoir la détecter.
La feature extraction peut être réalisée de plusieurs manières, mais il s’agit souvent d’une implémentation exacte ou modifiée des techniques classiques que nous avons vues. Le machine learning permet de tuner automatiquement leurs paramètres de la meilleure façon pour le but déclaré – ici détecter les motos – dans autant de conditions que possible.
Neural networks
Une architecture de machine learning très populaire est le réseau de neurones. Il se décline en de très nombreuses variantes. Imaginons que nous cherchions à créer un réseau de neurones qui détecte la présence ou l’absence de moto dans une image.
Son principe est simple : l’entrée du système est une image dans notre cas. Les pixels de l’image excitent les neurones à l’entrée du réseau, de la même façon que nos récepteurs visuels excitent notre nerf optique.
Ensuite, les couches centrales sont impactées, car tous les neurones sont connectés. Mais chaque neurone est impacté un peu différemment par ses précédents. La force de l’impact est déterminée, pour chaque neurone, par un paramètre – une sensibilité, si on veut. Il y a aussi, pour chaque neurone, un paramètre qui définit à quel point il transmet son excitation aux suivants. Il peut y avoir énormément de couches centrales. Dans notre cas, les premières couches centrales feront l’extraction des features, et les suivantes combineront les features trouvées pour en déduire quelque chose.
Enfin, la dernière couche de neurones contient dans notre exemple un seul neurone. Si ce neurone est très excité, c’est que le réseau a trouvé une moto, sinon non.
Il reste à entraîner le réseau, c’est-à-dire affiner les paramètres, les sensibilités des neurones, pour que le résultat soit bon. Et comme un réseau neuronal est très flexible, il y a de bonnes chances qu’il arrive à modéliser ce qu’on cherche. Les neurones peuvent être tous semblables et appliquer les mêmes calculs, ou non. C’est au choix.
Ici, on ferait bien de programmer les premières couches de neurones pour appliquer les méthodes classiques de machine vision. Nous savons qu’elles sont probablement utiles à la tâche en cours, alors plutôt qu’attendre que l’entraînement du réseau les réinvente, autant les intégrer.
Cela permet de gagner énormément de temps et d’argent, car l’entraînement d’un réseau peut être très long et coûteux en énergie, en plus de demander du matériel haut de gamme.
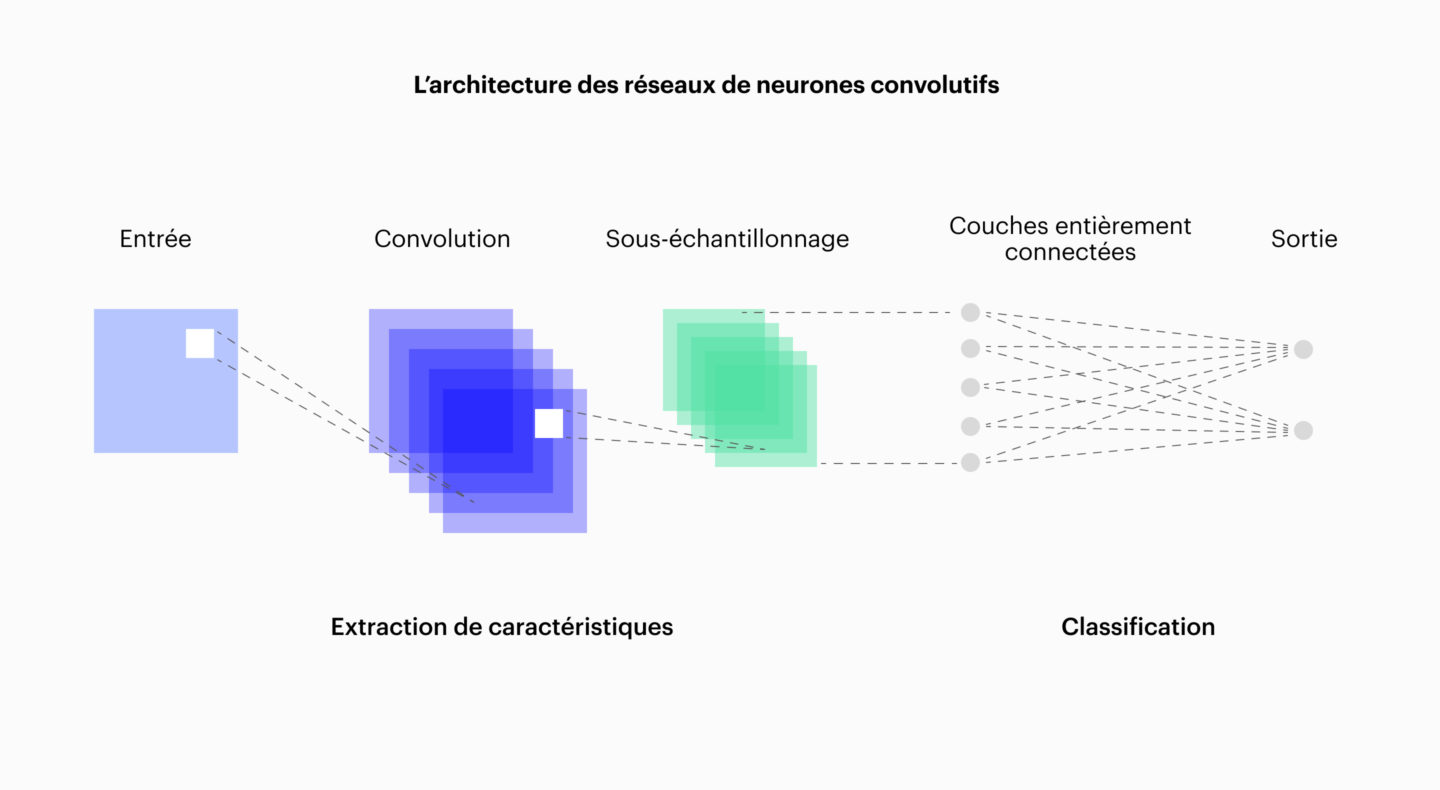
Il est possible de faire une autre amélioration encore, notamment dans le domaine de la machine vision : c’est le CNN, le réseau de neurones convolutifs.
Convolutional neural networks
Le CNN est une amélioration du simple réseau de neurones, car il implémente l’extraction de features d’une façon qui est plus adaptée aux images. Voici un exemple pour illustrer.
Si on cherche une moto dans une image, elle pourrait être dans la partie gauche ou la partie droite. Pourtant, ça ne change rien au fait que c’est une moto. Et bien, le réseau de neurones de tout à l’heure ne perçoit pas du tout les deux cas de la même façon : pour lui, des neurones tout à fait différents sont excités par un cas et par l’autre. Pour qu’il reconnaisse des motos à gauche comme à droite, il devra “apprendre” que ces deux cas sont identiques. Cela ne va pas de soi, et prend davantage de temps d’entraînement.
Le génie du CNN, est que les stimulis identiques à leur position près excitent naturellement les mêmes neurones, ce qui les rend beaucoup plus rapides à entraîner pour des tâches de machine vision.
Cela en fait donc des excellents candidats. Ci dessous, un diagramme d’exemple.
Conclusion
La machine vision est un domaine qui a ses difficultés, et qui propose rarement (voire jamais) des solutions clé-en-main qui marchent dans tous les cas. C’est un domaine résolument statistique, ou les certitudes sont toutes relatives.
Toutefois, on la maîtrise de plus en plus, notamment grâce aux avancées en deep learning (qui ne sont ni plus ni moins que d’énormes réseaux de neurones) conjuguées aux optimisations comme les CNN et la programmation explicite des méthodes classiques.
Il existe malgré tout de nombreux moyens de tromper les systèmes de vision basés sur le machine learning. On parle là de machine learning adversarial ou de dataset poisoning. Ainsi, on ne peut pas se reposer sur nos lauriers, et il y a encore beaucoup de choses à découvrir.



