
Generative artificial intelligence is increasingly finding its way into the tools we use on a daily basis. Whether it’s office software like Word or Google Sheets, or search engine results, AI is becoming omnipresent. This trend reflects a true race for productivity, as well as fierce competition between major players in the field — notably Anthropic, Google, and OpenAI — all aiming to capture market share.
In this article, we explore generative AI in a broad sense: from models such as LLMs (Large Language Models) and SLMs (Small Language Models), to intelligent agents, and how we use them in our everyday work as developers.
At Apptitude, we closely monitor the evolution of these technologies. With generative AI fundamentally altering the work of concept developers, it’s more important than ever for us to stay up to date, so we can consistently deliver projects of the highest standard. Initially adopted individually by a few developers, AI quickly generated collective interest, to the point that we decided to structure its use within our teams.
How do we use this new “toolbox” at Apptitude?
Over the past year, we have created an internal participatory team (a guild) dedicated to AI. This guild acts as a point of reference and enables us to delve into a range of topics: ways of working, new tools, automation…
The guild takes an incremental approach: a new LLM model is released? We test it and measure its effectiveness. A new tool? We try it out. The goal is simple: to quickly spot potential solutions that can improve efficiency and save time on certain tasks. As the tools evolve rapidly, it’s essential to maintain a highly agile approach and remain open to new practices.
The First Tool for Developer-Craftsmen: an IDE
The integrated development environment (IDE) allows a developer to produce code. It’s a kind of super notepad, with the most well-known today being VS Code and IntelliJ.
When we set up our “AI Guild”, we wanted to see whether our IDE could become even more powerful. So, each of us tested AI-augmented IDEs such as Cursor, Windsurf… and extensions integrated into our IDE like Cline.

The first conclusion is simple: with AI now integrated into our working environment, we feel more productive, progressing faster, especially on certain targeted tasks. However, it remains difficult at this stage to precisely measure the overall impact across our teams, as this initiative is still recent. Nevertheless, we’ve started collecting some indicators: comparing estimated time versus actual time spent on a task, with or without the use of AI, as well as analysing any overruns in our projects.
One striking sentiment has emerged among several team members: we’re no longer alone when facing blockers. At any time, we can call on an AI to do on-demand pair programming. This has profoundly changed the way we work: AI has almost naturally integrated itself into our daily workflow, and calling on it whenever needed is very easy.
This is exactly what tools like Cursor illustrate well. With $300 million in annual revenue, Cursor shows that developers aren’t necessarily looking for brand new tools, but rather seamless integrations into their existing environments. As Cursor is a derivative of VS Code, switching from VS Code to Cursor comes with no interface change — just new features, while the tool’s look and feel remains familiar. Anthropic, with Claude Code, is moving in the same direction: an AI assistant available directly in the terminal. More recently, Google followed suit with the launch of Gemini CLI.
For which tasks can AI be used?

LLMs and agents are “great”, but not for everything. The guild has taken on the role of identifying several use cases where AI is relevant. This continues to be our focus, and for now, here is our feedback:
Specifying a feature
Understanding concretely what it involves to develop it. Specialised models like Gemini and Claude are a great help in such cases. Open-source models like Qwen 2.5 and Kimi 2 also perform reasonably well.
Structuring according to a defined architecture
AI is particularly effective when the architecture is clear and decoupled. For example, in our composable front-end interfaces, with few dependencies between components, it better understands what it’s handling and generates more accurate code with fewer errors. On the other hand, in architectures that are more interdependent, with lots of cross-dependencies or hidden logic, AI finds it more difficult to understand the structure and produce correct, meaningful code.
Completing our reflections
With increasingly complex projects, it is sometimes necessary to revisit our implementation plans: ensuring everything is robust, secure, and intelligently designed. Asking an AI to provide a rigorous critique of our specifications can challenge our technical vision and identify any gaps, if there are any. It acts as an external eye. While it’s no replacement for an architect, it adds a valuable perspective before the implementation phase.
Cleaning and processing data
What could be worse than handling .csv files manually? It’s tedious, time-consuming, and adds no real value for the client or the developers. AI steps in here to create small programmes that meet this need. For example, imagine we have data from 10 questionnaires stored in a csv table. To exploit this data, we can ask a local model to process, structure, and organise the data, then output it in an easily manageable format. The data never leaves the machine and is properly formatted for further use. Creating a customised programme to perform this task might have taken two hours, but with AI, it’s done in five minutes. For this kind of micro-programme, we use ollama, an aggregator of LLM models installed on our machines. It allows us to run open-source models locally without internet access. These are not the most cutting-edge models, but for tasks like this, they work very well.
Testing our applications
Delivering an application without testing is unthinkable. AI enables the creation of automated tests from our specifications. The more precise our specifications are, the more robust tests we can create upstream of development, covering all expected behaviours. This allows us to develop applications directly using a TDD (Test Driven Development) approach.
Smoothing the onboarding of a new team member on a project
AI can help understand a project as a whole by ingesting the codebase. The AI model can produce detailed documentation of the code based on what it understands. Of course, it won’t have the full context, but it will provide the main outlines to help understand and immerse more quickly.
Documenting
Project documentation helps avoid knowledge loss. When we pick up a project a year later for maintenance, having precise documentation is a real time-saver. The problem? Writing documentation is a long and tedious task. Thanks to AI, each feature in our projects can be clearly documented. It can also update the documentation progressively as the project develops.
Pre-written code to start a project
This is repetitive code, often necessary, but not very interesting to write manually: file structures, component initialisation, routes, services, error handling, etc. AI is very efficient at this stage because it’s always the same.
For which tasks is AI not relevant?
Here are a few examples where AI is not relevant, or even completely off-topic.
Choice of technologies or libraries
AI can suggest tools or frameworks, but it often lacks up-to-date information or an understanding of the project context. Choosing a relevant library relies on our ability to explore documentation, compare community opinions, and judge the maturity or maintenance of a tool. In short, it is a task requiring human monitoring and discernment.
Designing complex architectures
Architecture cannot be guessed; it is built. It results from discussions with the client, technical trade-offs, and specific business constraints. AI can suggest patterns or evaluate certain choices, but without context (roadmap, team, history, priorities), its recommendations are often too generic or unsuitable.
Technical debt analysis or deep refactoring
Analysing legacy code or technical debt cannot be done without a detailed understanding of the business, past decisions, and compromises made. AI may flag apparent “bad practices,” but it does not always understand why they exist or what they imply. It then risks recommending a complete rewrite instead of guiding a genuine refactoring strategy.
Effort estimation
Estimates generated by AI are often very rough, even arbitrary. It has neither insight into the actual level of complexity, knowledge of the team, nor awareness of dependencies between tasks. As a result, it may produce appealing figures, but without any solid basis.
Techniques and working environment

The quality of an AI’s responses depends on several factors, and in most cases, it needs to be properly guided. We have tested several approaches to frame it.
“rules.md” rule files
The .md (Markdown) format is easily readable and allows us to structure a text document with different heading levels, lists, etc. We record our best practice rules and standards there. This acts as a framework with permissions and prohibitions.
Still within a .md file, or another easily readable file, we can provide the architecture in a clear format. The AI can refer to this and align itself with our project knowledge. This prevents it from going completely off track or hallucinating.
We can also align the AI precisely on task definitions according to our agile project methodology. Our projects are often broken down into major features, which are then split into tickets and tasks. We can therefore ask the AI to create a folder @docs/delivery where it will generate one .md file per task. This allows us to jump from one task to another and ensure progress: we note timestamps for each task, tests to write… These tasks are defined by the project manager, who prepares the specifications beforehand. The AI will update the file by itself and keep the context of each task.
The “ETA” file
It allows the AI to keep the project’s “high-level” context up to date. It acts as a checkpoint at the end of each task, with the AI updating this file as well as ourselves. This is useful if something goes wrong. Imagine having a crash in your editor; this file will serve as a checkpoint and allow you to resume exactly where you left off.
The “git-flow.md” file
It outlines the git best practices per project to avoid misunderstandings about how branches should be managed. It is also useful for developers.
MCP servers
An MCP server is a small endpoint where our AI can retrieve the precise documentation of a specific library. This is very useful to provide maximum context to our AI and to prevent hallucinations about what it can or cannot use. There are many such servers. We notably use Context7, which makes a large number of documentations available directly within our code editors.
The art of prompting, planning, but above all clear description
Although AI may seem magical, the right technical knowledge is needed to make it do what we want. It is primarily a matter of language and technical concepts: the more precise we are about what we want technically, the more we understand what we are talking about, the better the AI’s approach will be. It is not enough to tell the AI “code this” or “code that”. If you do not understand what it is doing, which fundamental concepts it is manipulating, it is lost from the start. You can give it a very high-level approach with, for example, these instructions:
“Create an application with a map that allows me to reference all the protected rivers in Switzerland along with points of interest.”
On paper, this will probably work well! The AI will connect a database, create an interface, implement the data retrieval logic, and it will be functional. Great for a quick Proof of Concept (PoC), then! (This also raises questions about the relevance of no-code tools in the age of AI, but that’s another topic).
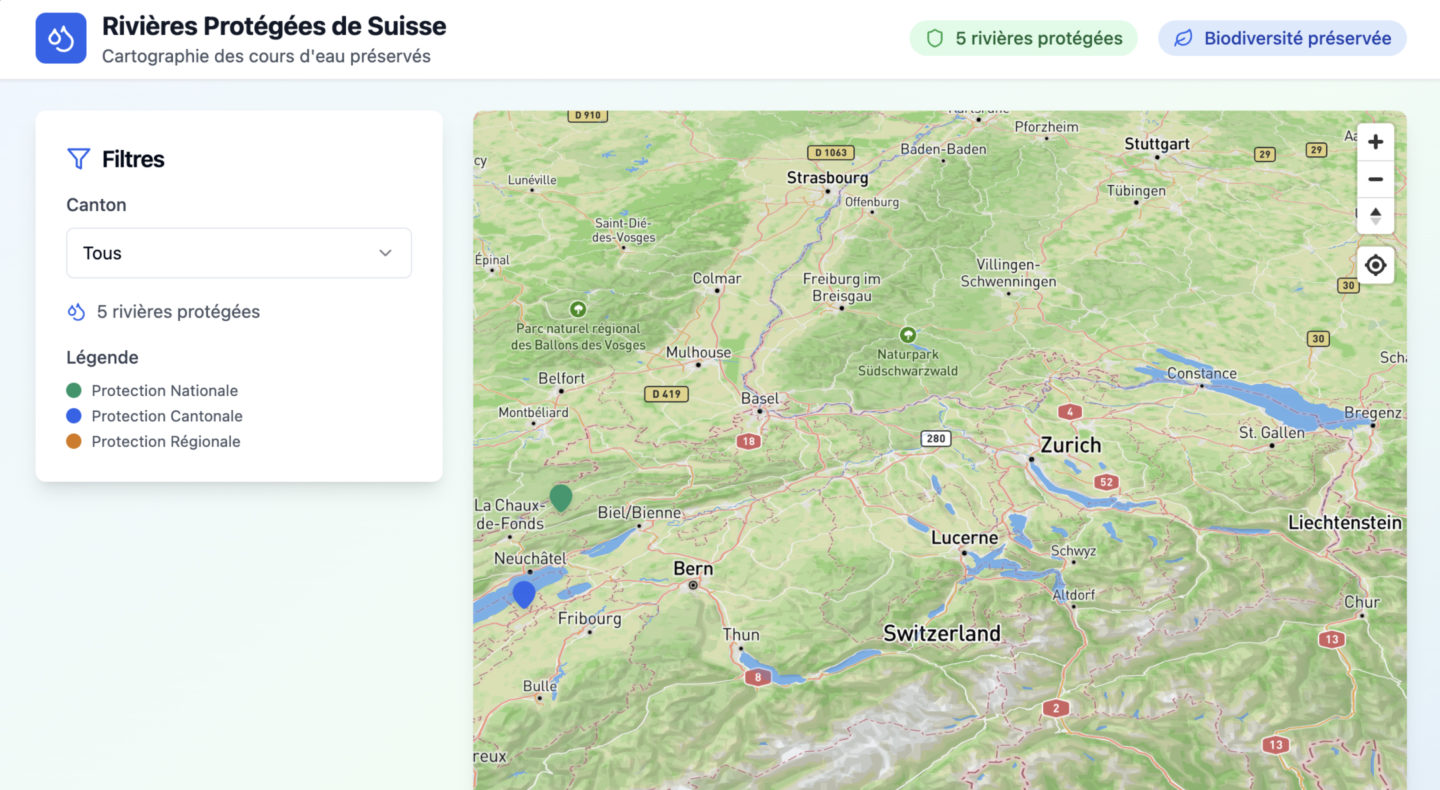
Unfortunately, at some point, you will want to add features. You will want to stick as closely as possible to your vision, to your product, and anything that wasn’t accounted for upfront will be complex to add.
The bigger the project gets, the more context the AI loses. You also won’t have specified how to do it, because you’ll have stayed at a “high level.” So it will take the liberty to do things “its own way,” not necessarily in the cleanest or most sustainable manner.
This will result in architectural issues, and as soon as you need to understand what’s going on, technical expertise will be required. This can only be done with a human keeping an eye on the work, not blindly delegating to models or agents.
At Apptitude, we have identified an AI approach that works well
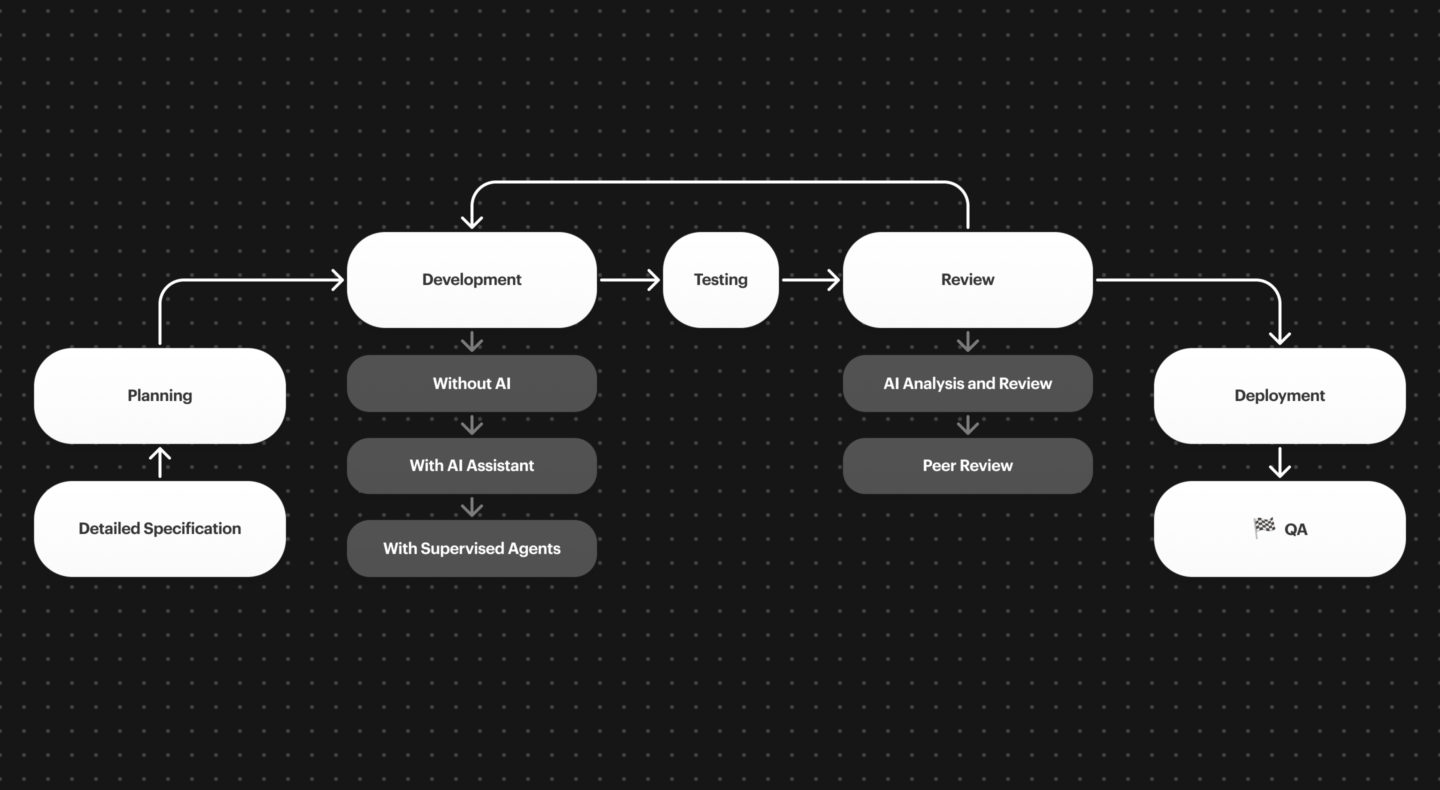
We can use AI at several points in our production chain.
For example, during the development of a feature on a project, AI can intervene at multiple levels — whether during development, specification, or even code review. For code review, we test automated solutions like Sonar for quality, as well as CodeRabbitIA for reviewing git branches, and GitHub Copilot’s integrated AI directly on GitHub. As you can see in the diagram, there is always human validation. Nothing is left to chance; we never leave AI to operate autonomously. The human always has the final say.
AI as a product and as a feature
We also develop projects with integrated artificial intelligence as a feature. This is part of a broader approach to make our projects even more comprehensive and bespoke by incorporating Data Science in the broadest sense. AI thus becomes a fully-fledged feature and unlocks new types of projects. In 2025, we are working on several projects that integrate AI as a feature. For example, we are developing a local-first Retrieval Augmented Generation (RAG) system for our clients, where they can connect their documents and have an LLM that can interact with them and extract information from all the documents.
AI unlocks new use cases, and we are gradually integrating these tools into the solutions we offer our clients.
Limits, doubts and caution
Generative artificial intelligence, powerful as it may be, is not a magic solution. Its use in our daily work as developers has shown us that it can be remarkably effective… but also a source of frustration, errors, or even wasted time if it is poorly used or insufficiently guided.
Sometimes approximate results
Even with a clear prompt, the AI can produce code that compiles… but does not respect the product’s intentions, internal conventions, or business logic. Constant validation, testing, and review are necessary. Overconfidence can lead to implementations disconnected from real needs, resulting in over-engineering.
The question of plagiarism and code ownership
Using a model trained on billions of lines of open-source code raises legal questions. Who owns the generated code? Could it contain excerpts under restrictive licenses? We do not yet have all the answers, but we remain attentive to these issues.
Data confidentiality
We also have concerns regarding privacy and confidentiality. It would be irresponsible to blindly upload client code or documents to cloud-based tools without safeguards. Therefore, we have implemented very concrete practices:
- No sensitive data sent to LLMs not hosted on our machines.
- Enable “Privacy” mode on tools such as Cursor.
- Block access to certain critical files by models: environment variable files, sensitive data, client data…
- Use local LLM models like Mistral or DeepSeek via Ollama.
- Isolate the code sent to the model to limit context leakage.
- With our clients, we comply with imposed rules: if there is no authorisation to use AI, then no AI is used.
The illusion of autonomy
AI agents promise a lot, but in reality, their ability to reliably chain together complex tasks remains limited. The dream of an autonomous developer driven by AI is still far off. And that’s a good thing: the human stays in control, because they know the product, its constraints, and the true objectives. The developer is at the heart of a project and its challenges, which is not the case for AI.
Incomplete evaluation metrics
There are several useful indicators for tracking the performance evolution of AI models, such as SWE-bench (evaluation on real bugs) or LMArena (multi-model comparisons). These tools have become benchmarks in the field.
However, the evaluation methods they use often have biases (limited datasets, lack of business context, artificial problem formulations). They do not always allow for judging the real relevance of a model in a concrete project. Thus, they are not absolute trust indicators but rather reference points to be complemented with real-world experience.
Conclusion : AI is changing the way we work
We see it every day: AI is transforming how we work. It does not replace us, but accompanies us throughout a project. At Apptitude, it saves us time on repetitive and time-consuming tasks, helps us resolve certain situations more quickly, and opens up perspectives we might not have considered otherwise. It broadens our range of possibilities.
AI remains a powerful tool, but not a magic one. It does not replace thinking, decision-making, or the rigorous standards required at every stage of a project. It has its limits, blind spots, and use cases. The key is to use it where it truly adds value.
So, ready to boost your lines of code? Let’s talk!



