
L’intelligence artificielle générative s’invite de plus en plus dans les outils que nous utilisons au quotidien. Qu’il s’agisse de logiciels bureautiques comme Word, Google Sheets ou encore dans les résultats du moteur de recherche, l’IA devient omniprésente. Cette tendance s’inscrit dans une véritable course à la productivité, mais aussi dans une compétition féroce entre les grands acteurs du secteur avec notamment Anthropic, Google, OpenAI qui veulent capter des parts de marché.
Dans cet article, nous abordons l’IA générative au sens large : des modèles de type LLM (Large Language Models) ou SLM (Small Language Models), jusqu’aux agents intelligents, et comment nous les utilisons dans notre quotidien de développeurs.
Chez Apptitude, nous suivons de près l’évolution de ces technologies. L’IA générative transforme en profondeur nos métiers de concepteurs, et il est essentiel pour nous de rester en veille constante afin de continuer à livrer des projets toujours plus qualitatifs. D’abord adoptée individuellement par certains développeurs, l’IA a rapidement suscité un intérêt collectif, au point que nous avons décidé de structurer son usage au sein de nos équipes.
Comment utilisons-nous cette nouvelle “boîte à outils” chez Apptitude ?
Depuis une année, nous avons créé en interne une équipe participative (une guilde) sur le sujet de l’IA. Cette guilde agit comme référent et permet d’aller en profondeur sur des problématiques variées : manière de travailler, nouveaux outils, automatisation…
Cette guilde a une approche incrémentale : un nouveau modèle de LLM sort ? Nous essayons et mesurons son efficacité. Un nouvel outil ? Nous essayons. L’enjeu est simple : identifier à l’œil les potentielles solutions pour gagner en efficacité et en temps sur certaines tâches. Les outils évoluent vite, et il faut donc avoir une approche très agile sur le sujet et rester ouvert à de nouvelles pratiques.
Le premier outil pour les artisans développeur : un IDE
L’environnement de développement intégré (IDE), permet à un développeur de sortir du code. C’est une sorte de super bloc note dont les plus connus aujourd’hui sont VS Code et IntelliJ.
En mettant en place notre “Guilde IA”, nous avons donc voulu voir si notre IDE pouvait devenir encore plus puissant. Nous avons donc testé chacun de notre côté des IDE augmentés par IA : Cursor, Windsurf… puis des extensions intégrées dans notre IDE comme Cline.

Le premier bilan est simple : avec l’IA désormais intégrée à notre environnement de travail, nous avons le sentiment d’être plus productifs, d’avancer plus vite, en particulier sur certaines tâches ciblées. Il reste néanmoins difficile, à ce stade, de mesurer précisément l’impact à l’échelle de l’ensemble de nos équipes, car cette initiative reste récente. Nous avons toutefois commencé à collecter quelques indicateurs : comparaison du temps estimé et du temps réellement passé sur une tâche, avec ou sans recours à l’IA, ainsi que l’analyse des éventuels dépassements dans nos projets.
Un ressenti marquant est revenu chez plusieurs membres de l’équipe : on n’est plus seul face aux blocages. À tout moment, on peut solliciter une IA pour faire du pair programming à la demande. Cela change profondément notre façon de travailler : l’IA s’est intégrée, presque naturellement, dans notre workflow quotidien et la solliciter quand on le souhaite est très facile.
C’est précisément ce que des outils comme Cursor illustrent bien. Avec 300 millions de dollars de chiffre d’affaires annuel, Cursor montre que les développeurs ne cherchent pas nécessairement de nouveaux outils, mais plutôt des intégrations fluides dans leur environnement existant. Cursor étant un outil dérivé de VS Code, en passant de VS Code à Cursor, il n’y a aucune différence d’interface, il y a juste des nouvelles fonctionnalités, mais l’apparence de l’outil reste très proche. Anthropic, avec Claude Code, va dans le même sens : un assistant IA disponible directement dans le terminal. Et plus récemment, Google a suivi avec le lancement de Gemini CLI.
Pour quelles tâches peut-on utiliser l’IA ?

Les LLMs et les agents “c’est super”, mais pas pour tout. La guilde a eu comme rôle d’identifier plusieurs cas où l’IA est pertinente. Cela continue d’être notre focus et pour l’instant, voici notre retour d’expérience :
Spécifier une fonctionnalité
Savoir concrètement ce que cela implique pour la développer. Les modèles spécialisés comme Gemini et Claude sont d’une grande aide dans ce type de cas. Les modèles open sources comme Qwen 2.5 et Kimi 2 ne sont pas mauvais également.
Structuration selon une architecture définie
L’IA est particulièrement efficace quand l’architecture est claire et découplée. Par exemple, dans nos interfaces front-end en mode “composable”, avec peu de dépendances entre composants, elle comprend mieux ce qu’elle manipule et génère un code plus juste, avec moins d’erreurs. À l’inverse, dans des architectures plus couplées, avec beaucoup de dépendances croisées ou de logique implicite, l’IA a plus de mal à s’y retrouver et donc à produire du code juste et pertinent.
Compléter nos réflexions
Avec des projets de plus en plus complexes, il faut parfois faire des repasses sur nos plans d’implémentation : s’assurer que tout est robuste, sécurisé, et intelligemment construit. Demander à une IA de faire une critique sévère de nos spécifications peut challenger notre vision technique, et identifier les trous dans la raquette, s’il y en a. Elle agit comme un œil extérieur. Elle ne remplace pas un architecte, loin de là, mais elle vient compléter la vision avant d’implémenter.
Nettoyer et traiter des données
Quoi de pire que de traiter des .csv à la main ? C’est pénible, chronophage et ça n’a strictement aucune valeur ajoutée pour le client et pour les développeurs. L’IA intervient ici pour nous faire des petits programmes qui répondent à ce besoin. Par exemple, imaginons que nous avons des données de 10 questionnaires qui sont dans un tableau csv. Pour exploiter ces données, on peut demander à un modèle en local de traiter, structurer et ordonner les données, puis de les sortir dans un format facilement manipulable. Les données ne quittent pas la machine et sont formatées correctement pour les exploiter ensuite. La création d’un programme personnalisé permettant d’effectuer cette tâche aurait peut-être pris 2 heures, mais avec l’IA, c’est fait en 5 minutes. Pour faire ce type de micro programme, nous utilisons ollama, un agrégateur de modèles LLM installé sur nos machines. Il nous permet d’installer en local des modèles open source utilisables sans internet. Il ne s’agit pas des modèles les plus à la pointe, mais pour des tâches comme celles-ci, ça fonctionne très bien.
Tester nos applications
Livrer une application sans avoir effectué de test, ce n’est pas envisageable. L’IA permet, à partir de nos spécifications, de créer des tests automatisés. Plus on est précis dans nos spécifications, plus on peut créer des tests robustes en amont du développement, avec tous les comportements attendus. Cela permet d’avoir une application développée directement avec une approche de TDD (Test Driven Development).
Fluidifier l’arrivée d’un nouveau membre sur un projet
Une IA peut aider à comprendre un projet dans son ensemble, en faisant de l’ingestion d’une base de code. Le modèle d’IA peut nous sortir une documentation détaillée du code avec ce qu’elle en comprend. Bien sûr, elle n’aura pas tout le contexte, mais cela nous donnera les grandes lignes pour comprendre et s’immerger un peu plus rapidement dedans.
Documenter
La documentation d’un projet permet d’éviter de perdre de la connaissance. Quand nous reprenons un projet, un an plus tard pour de la maintenance, trouver une documentation précise est un vrai gain de temps. Le problème ? Faire une documentation est un travail long et fastidieux. Dans nos projets et grâce à l’IA, chaque fonctionnalité peut donc être documentée clairement. Elle peut également mettre à jour la documentation au fur et à mesure que le projet avance.
Le code pré-écrit pour démarrer un projet
C’est du code répétitif, souvent nécessaire, mais peu intéressant à écrire manuellement : structures de fichiers, initialisation de composants, routes, services, gestion des erreurs, etc. L’IA est très efficace sur cette étape parce que c’est tout le temps la même chose.
Pour quelles tâches l’IA n’est pas pertinente ?
En vrac, voici quelques exemples ou l’IA n’est pas pertinente, voire complètement hors sujet.
Choix de technologies ou de librairies
L’IA peut suggérer des outils ou frameworks, mais elle manque souvent d’informations actualisées ou de compréhension du contexte du projet. Le choix d’une librairie pertinente repose sur notre capacité à explorer la documentation, confronter les avis de la communauté, et juger de la maturité ou de la maintenance d’un outil. Bref, c’est un travail de veille et de discernement humain.
Conception d’architectures complexes
Une architecture ne se devine pas : elle se construit. Elle résulte de discussions avec le client, d’arbitrages techniques et de contraintes métier précises. L’IA peut proposer des patterns ou juger certains choix, mais sans contexte (roadmap, équipe, historique, priorités), ses recommandations sont souvent trop génériques ou inadaptées.
Analyse de dette technique ou refonte en profondeur
L’analyse d’un legacy code ou d’une dette technique ne peut pas se faire sans compréhension fine du métier, des décisions passées, et des compromis qui ont été faits. L’IA peut signaler des “mauvaises pratiques” apparentes, mais elle ne comprend pas toujours pourquoi elles existent ni ce qu’elles impliquent. Elle risque alors de proposer de tout réécrire… au lieu de guider une vraie stratégie de refonte.
Estimation de charges
Les estimations générées par l’IA sont souvent très approximatives, voire arbitraires. Elle n’a ni vision du niveau de complexité réelle, ni connaissance de l’équipe, ni conscience des dépendances entre les tâches. Résultat : elle peut produire des chiffres séduisants, mais sans fondement.
Techniques et environnement de travail

La qualité des réponses d’une IA dépend de plusieurs facteurs, et dans la plupart des cas, il faut bien la guider.. Nous avons pu tester plusieurs approches pour la cadrer.
Les fichiers de règles “rules.md”
Le format .md (Markdown) est un format facilement lisible qui nous permet de structurer un document texte avec des niveaux de titres différents, des listes, etc. Nous y inscrivons nos règles de bonnes pratiques, nos standards. Cela agit comme un cadre avec des autorisations et des interdictions.
Toujours dans un fichier .md, ou dans un fichier facilement lisible, nous pouvons lui fournir l’architecture dans un format clair. L’IA peut s’y référer et s’aligner avec notre connaissance du projet. Cela évite qu’elle soit complètement à côté de la plaque et qu’elle hallucine.
Nous pouvons également aligner l’IA sur le la définition des tâches précisément en accord avec notre méthodologie projet agile. Nos projets sont souvent découpés par grandes fonctionnalités qui sont par la suite découpées en tickets et tâches. On peut donc demander à l’IA de faire un dossier @docs/delivery dans lequel elle viendra faire un fichier .md par tâche. Cela permet de sauter d’une tâche à l’autre et de s’assurer que tout avance bien : on note le timestamps pour chaque tâche, les tests à écrire… Ces tâches sont découpées selon le chef de projet qui aura fait les spécifications en amont. L’IA viendra mettre à jour toute seule le fichier, et gardera le contexte de chaque tâche.
Le fichier “ETA”
Il permettra à l’IA de garder le contexte “haut niveau” du projet à jour. Cela fait office de checkpoint à chaque fin de tâche, l’IA viendra mettre à jour ce fichier et nous aussi. C’est utile si quelque chose ne se passe pas comme prévu. Imaginez que vous ayez un crash dans votre éditeur, ce fichier agira comme un checkpoint et permettra de reprendre là où nous nous étions arrêtés.
Le fichier “git-flow.md”
Il indique les bonnes pratiques git par projet afin d’éviter les mésententes sur la façon dont les branches s’écrivent. C’est utile aussi pour les développeurs.
Les serveurs MCP
Un serveur MCP est un petit endpoint ou notre IA peut récupérer la documentation précise d’une librairie précise. Très utile pour donner un maximum de contexte à notre IA et pour éviter des hallucinations sur ce qu’elle peut utiliser ou non. Il y en a une multitude. Nous utilisons notamment Context7 qui rend disponible un grand nombre de documentations directement dans nos éditeurs de code.
L’art du prompt, de la planification, mais surtout de la description claire
Bien que l’IA puisse paraître magique, il faut le bon bagage technique pour lui faire faire ce qu’on veut. C’est avant tout une affaire de langage et de notions techniques : plus on est précis sur ce qu’on veut techniquement, plus on sait de quoi nous parlons, plus l’IA aura la bonne approche. Il ne suffit pas de dire à l’IA “code ceci” ou “code cela”. Si vous ne comprenez pas ce qu’elle fait, quels concepts fondamentaux, elle manipule, c’est perdu d’avance. Vous pouvez lui donner une approche très haut niveau avec, par exemple, ces instructions :
“Fais-moi une application avec une carte qui me permet de référencer toutes les rivières protégées en Suisse avec des points d’intérêts ”
Sur le papier cela fonctionnera probablement bien ! L’IA connectera une base de données, fera une interface, fera la logique de récupération de données, et cela sera fonctionnel. Super pour un “PoC (Proof of Concept) rapide” donc ! (cela pose d’ailleurs la pertinence des outils no-code à l’ère de l’IA, mais c’est un autre sujet).
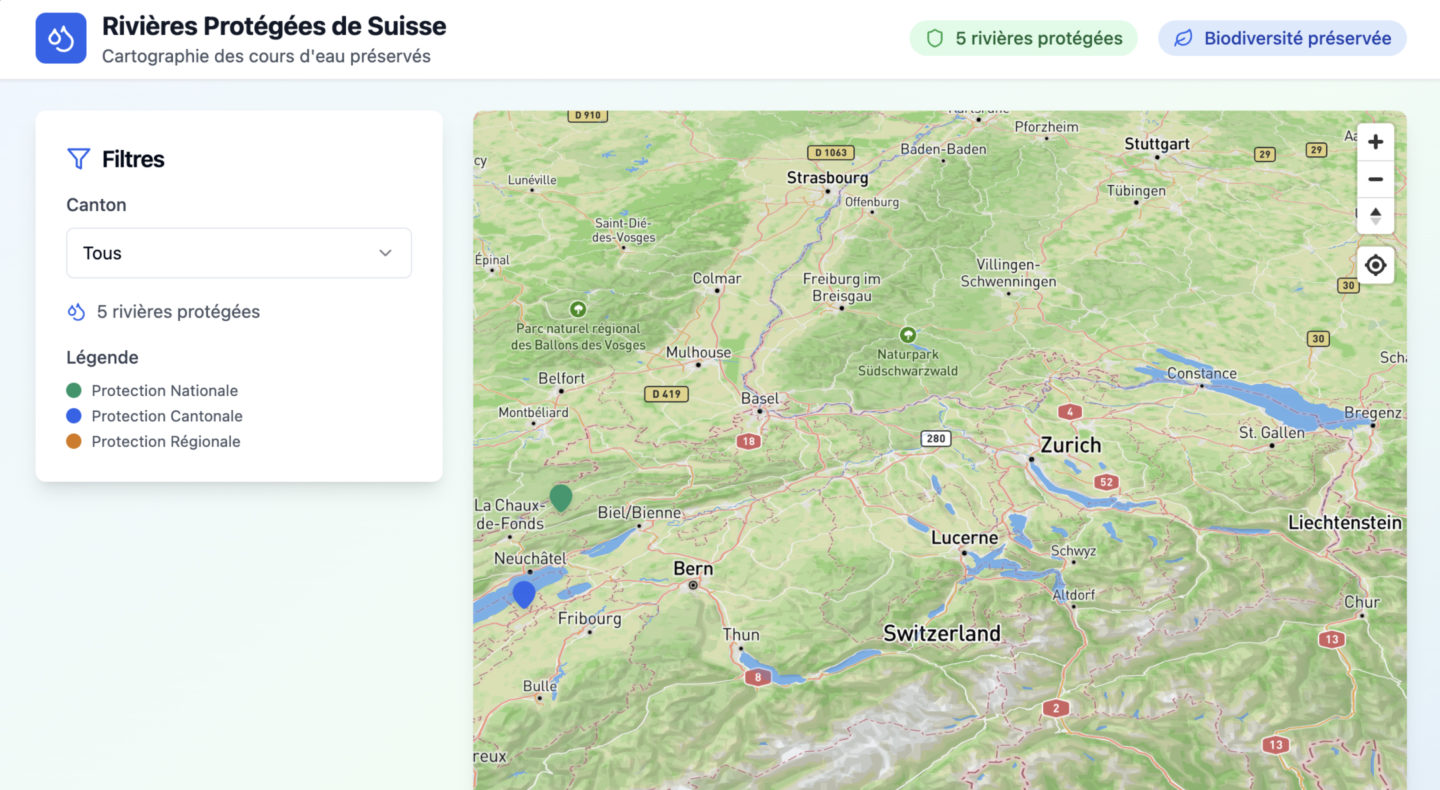
Malheureusement, à un moment donné, vous allez vouloir rajouter des fonctionnalités. Vous allez vouloir coller le plus possible à votre vision, à votre produit, et tout ce qui n’aura pas été pris en compte en amont sera complexe à rajouter.
Plus le projet grossit, plus l’IA perd du contexte. Vous ne lui aurez non plus pas précisé comment le faire, parce que vous serez resté en “haut niveau”. Elle prendra donc la liberté de faire “comme elle veut”, et pas nécessairement de la façon la plus propre et la plus pérenne.
Cela se traduira par des problèmes d’architecture et dès qu’il faudra aller comprendre ce qui se passe et un bagage technique sera nécessaire. Cela ne peut que se faire avec un humain qui garde un œil sur son travail, et non pas qui délègue aveuglément à des modèles ou à des agents.
Chez Apptitude, nous avons identifié une approche IA qui fonctionne bien :
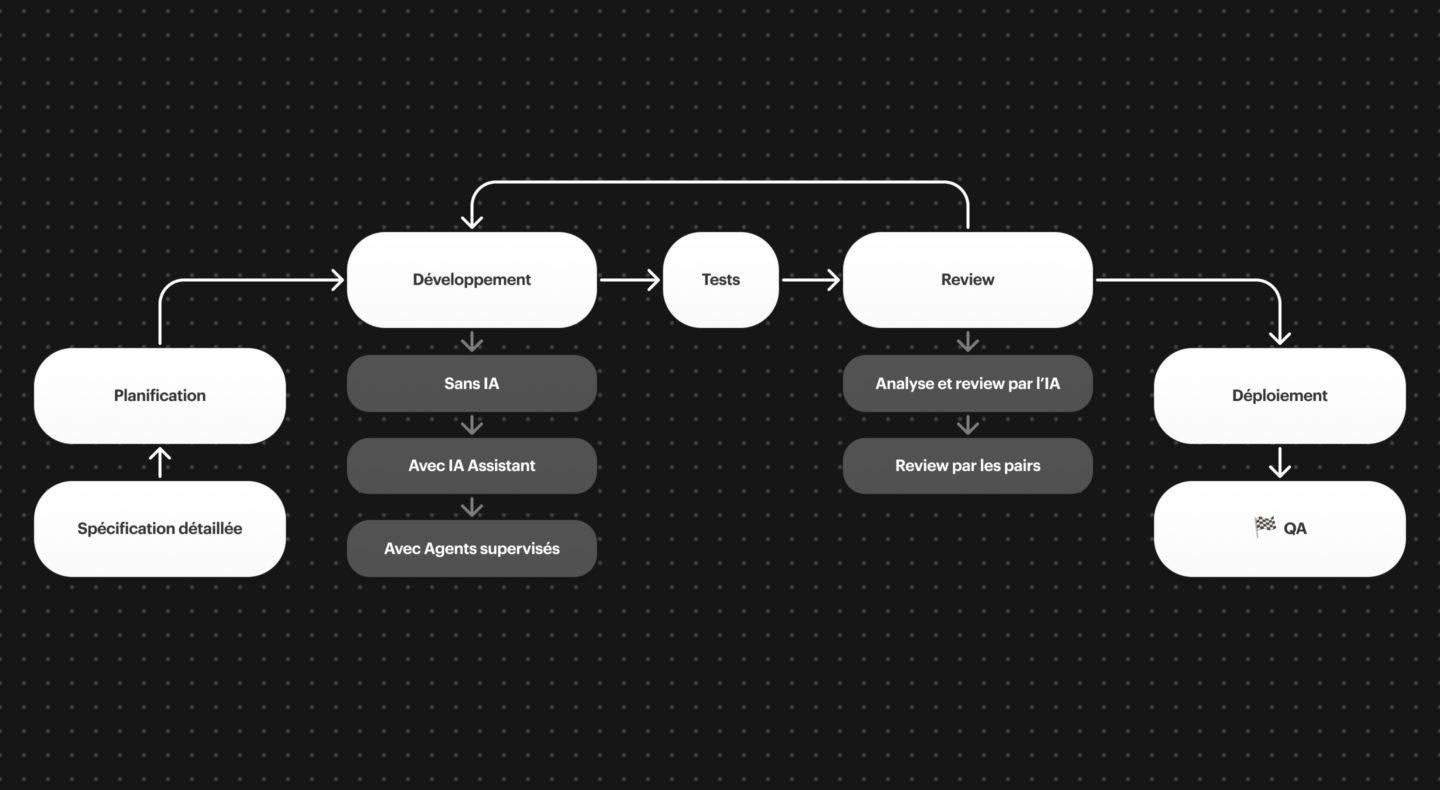
On peut utiliser l’IA à plusieurs endroits dans notre chaîne de production.
Par exemple, pour le développement d’une fonctionnalité sur un projet, l’IA peut intervenir à plusieurs niveaux. Que ce soit lors du développement, lors de la spécification, ou bien encore lors de la review du code. Pour la revue de code, nous essayons des solutions automatisées comme Sonar pour la qualité, mais aussi CodeRabbitIA pour la revue des branches git, ainsi que l’IA intégrée de Github copilot directement sur github. Vous le voyez aussi sur le schéma, il y a toujours une validation humaine. Rien n’est laissé au hasard, on ne laisse pas l’IA en autonomie. L’humain a toujours le dernier mot.
L’IA comme un produit et comme une fonctionnalité
Nous développons également des projets avec de l’intelligence artificielle intégrée comme fonctionnalité. Cela fait partie d’une réflexion plus globale de rendre nos projets encore plus complets et sur mesure en y intégrant de la Data Science au sens large du terme. L’IA devient ainsi une fonctionnalité à part entière et débloque des nouveaux types de projets. En 2025, nous travaillons sur plusieurs projets qui intègrent de l’IA comme fonctionnalité. Nous avons par exemple, le développement d’un RAG (Retrieval Augmented Generation) en “local first” pour nos clients ou ils peuvent connecter leurs documents, et avoir un LLM qui peut interagir avec et sortir des informations sur tous les documents.
L’IA débloque des nouveaux cas d’usages, et nous intégrons petit à petit ces outils dans les solutions que nous proposons à nos clients.
Des limites, des doutes et de la prudence
L’intelligence artificielle générative, aussi puissante soit-elle, n’est pas une solution magique. Son usage, dans notre quotidien de développeurs, nous a montré qu’elle peut être redoutablement efficace… mais aussi source de frustration, d’erreurs, voire de perte de temps si elle est mal utilisée ou insuffisamment cadrée.
Des résultats parfois approximatifs
Même avec un prompt clair, l’IA peut produire du code qui compile… mais qui ne respecte ni les intentions du produit, ni les conventions internes, ni la logique métier. Il faut constamment valider, tester, et relire. Un excès de confiance peut conduire à des implémentations déconnectées des besoins réels et donc à de la sur-ingénierie.
La question du plagiat et de la propriété du code
Utiliser un modèle entraîné sur des milliards de lignes de code open source soulève des questions juridiques. À qui appartient le code généré ? Peut-il contenir des extraits sous licence restrictive ? Nous n’avons pas encore toutes les réponses, mais nous restons attentifs à ces sujets.
La confidentialité des données
Nous avons aussi des réserves sur la vie privée et la confidentialité. Il serait irresponsable de pousser sans réfléchir du code ou des documents clients dans des outils cloud sans garanties. Nous avons donc mis en place des pratiques très concrètes :
- Aucunes données sensibles envoyées à des LLM qui ne sont pas sur nos machines.
- Activer le mode “Privacy” sur des outils comme Cursor.
- Bloquer l’accès à certains fichiers critiques aux modèles : fichiers de variables d’environnements, données sensibles, données clients…
- Utiliser des modèles LLM locaux comme Mistral ou DeepSeek, via ollama.
- Isoler le code envoyé au modèle pour limiter les fuites de contexte.
- Chez nos clients, nous respectons les règles imposées : si il n’y a pas d’autorisation d’utiliser IA, alors pas d’IA.
L’illusion de l’autonomie
Les agents IA promettent beaucoup, mais dans les faits, leur capacité à enchaîner des tâches complexes de façon fiable reste limitée. Le rêve d’un développeur autonome piloté par l’IA est encore loin. Et c’est tant mieux : l’humain garde la main, car c’est lui qui connaît le produit, ses contraintes, et les vrais objectifs. Le développeur se trouve au cœur d’un projet et de ses enjeux, ce qui n’est pas le cas de l’IA.
Des indicateurs d’évaluation incomplets
Il existe plusieurs indicateurs utiles pour suivre l’évolution des performances des modèles d’IA, comme SWE-bench (évaluation sur des bugs réels) ou LMArena (comparatifs multi-modèles). Ces outils sont devenus des références dans le domaine.
Cependant, les méthodes d’évaluation qu’ils utilisent comportent souvent des biais (datasets limités, absence de contexte métier, formulation artificielle des problèmes). Ils ne permettent pas toujours de juger de la pertinence réelle d’un modèle dans un projet concret. Ce ne sont donc pas des indicateurs de confiance absolus, mais des repères à compléter avec du terrain.
En conclusion, l’IA change notre façon de travailler
Nous le constatons chaque jour : l’IA transforme notre manière de travailler. Elle ne nous remplace pas, mais elle nous accompagne tout au long d’un projet. Chez Apptitude, elle nous fait gagner du temps sur des tâches répétitives et chronophages, elle nous aide à débloquer plus rapidement certaines situations, et elle nous ouvre des perspectives que nous n’aurions peut-être pas envisagées autrement. Elle élargit notre champ des possibles.
L’IA reste un outil puissant, mais pas magique. Elle ne remplace ni la réflexion, ni les choix à faire, ni l’exigence de rigueur nécessaire à chaque étape d’un projet. Elle a ses limites, ses angles morts, et ses cas d’usage. Il s’agit donc de l’utiliser là où elle apporte une réelle valeur.
Alors prêt à doper vos lignes de codes ? Discutons-en !



