
J’ai relativement souvent mentionné le « Reactive Manifesto » à différentes occasions chez Apptitude. Lors de discussions liées aux choix de développement ou d’architecture, mais également auprès de personnes non techniques – internes comme externes – pour leur illustrer que certains choix de développement peuvent et doivent être régis par des principes.
Le fait est qu’un « manifeste » illustre bien ce concept. Prenez les manifestes artistiques, comme le Dogme 95 dans le cinéma danois – j’aime toujours bien constater que notre métier a beaucoup de similitudes avec le domaine artistique – Bref, qu’on aime ou pas « Les Idiots », le résultat cinématographique correspond aux volontés du réalisateur parce que celui-ci s’est fixé une série de mesures et de contraintes lors de son tournage.
Dans le cadre de l’architecture de systèmes distribués, au lieu de débattre de choix techniques le « Reactive Manifesto » définit une charte. Une série de principes qui, s’ils sont respectés, contribuent à la mise en place d’un système stable et robuste.
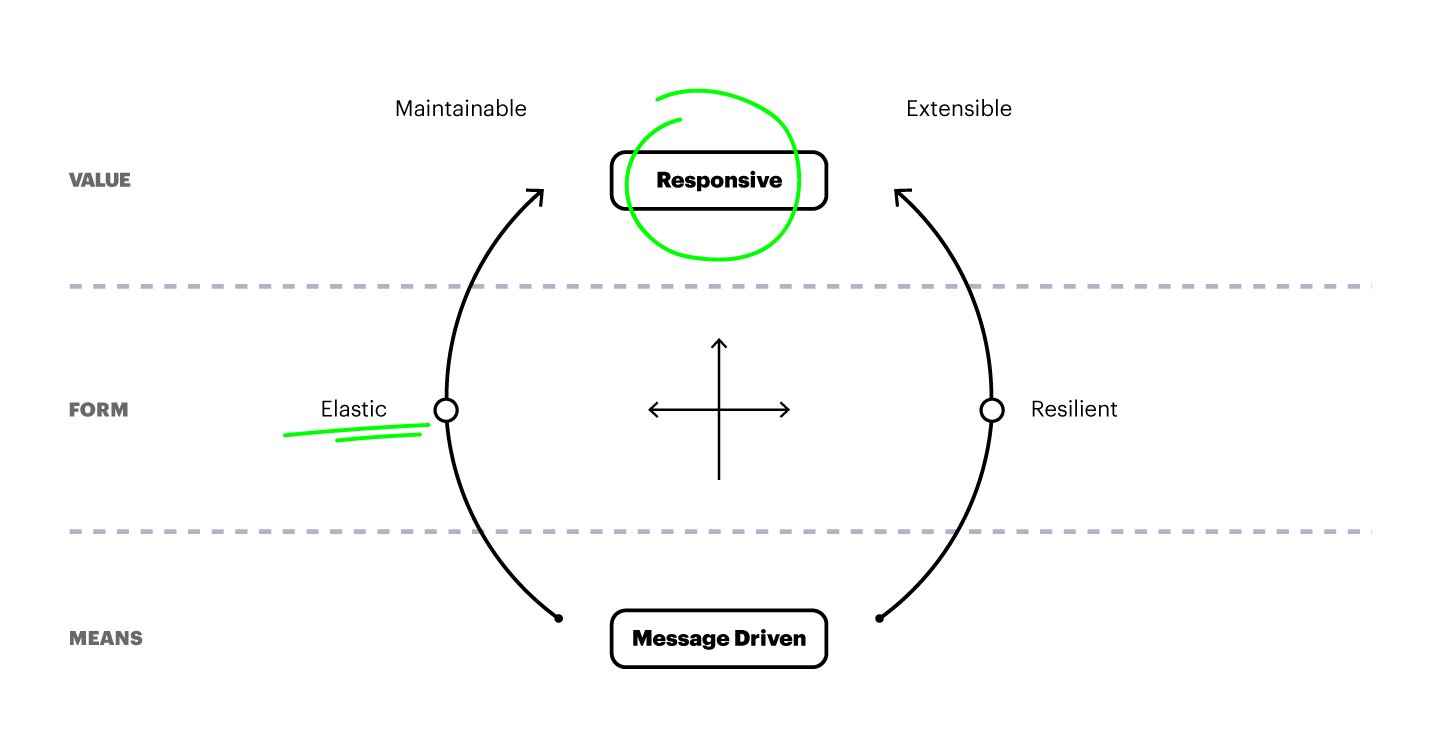
Responsive et Elastic
Intéressons-nous à deux mots clés qu’on retrouve dans le manifeste : « a system needs to be responsive » et « a system needs to be elastic ». Ces principes font sens dans tous types de projets distribués, tels les services web. Regardons ce qu’on entend par ces termes, ce qu’ils apportent et quelques pistes pour les mettre en place.
Imaginez une plateforme de réservation de chambres d’hôtes. Chacune des actions que vous faites est traduite par une requête réseau entre votre browser et une API REST, le back-end. Avant de pouvoir vous afficher le résultat de votre action (une recherche, une réservation, …) votre navigateur va devoir attendre la réponse du serveur. C’est ce temps d’attente qui est en cause du principe de « responsiveness »: quelles que soient les circonstances, un système doit répondre aux requêtes dans un délai donné. S’il n’est pas capable de traiter la requête, par exemple car il est surchargé, il devra répondre par une erreur mais également dans un temps imparti.
Pourquoi ? Parce que sinon il n’est possible pour l’utilisateur de savoir si il doit continuer d’attendre, ou si il doit recommencer et ceci est incompatible avec une bonne expérience utilisateur.
On prend le point de vue d’un utilisateur.
Mais un système est le plus souvent lui-même composé de sous systèmes, de « microservices ». Si un de ces services ne peut pas compter sur une réponse rapide du service qui traite sa requête, il reportera son attente sur ses clients, dégradant la performance générale du système.
Pour en revenir au système dans son ensemble et à l’expérience utilisateur : on considère qu’à partir d’une seconde d’attente entre l’action et le « feed-back« , l’utilisateur va percevoir le système comme étant dysfonctionnel…
Qu’est-ce qui rend nos services non responsifs ?
Probablement la charge. Autrement dit le nombre de requêtes le système doit traiter par minute (rpm). Plus celui-ci augmente, plus notre système sera chargé et plus il prendra de temps à répondre.
Pourquoi est-ce que la charge ralentit le système ?
Probablement parce qu’une ressource est saturée. Laquelle ? Eh bien ça dépend de ce que le système doit faire pour répondre aux requêtes. Cela peut être les entrées/sorties (réseau, disque) ou le CPU. La solution pour tenir plus de charge est d’augmenter les capacités du service surchargé (scale up). On distingue deux façons de ‘scaler’ un système. Le Vertical scaling : on augmente les capacités (plus de CPU, meilleure interface réseau), ou l’Horizontal scaling : on augmente le nombre d’instances du service pour que celles-ci se répartissent la charge, c’est à dire les requêtes entrantes.
On comprend assez rapidement que la seconde solution est moins limitée que la première. Aujourd’hui grâce à la containerisation des services et au cloud hosting, on peut de façon programmatique démarrer une nouvelle instance d’un service en une poignée de secondes.
Ce constat nous amène au second mot clef « elasticité »… Si d’une part on augmente le nombre d’instance d’un service afin de répondre à un nombre croissant de requêtes, on augmente aussi les coûts d’infrastructure de ce système. Or le « rpm » d’un service n’est pas stable. On peut avoir des pics de demande à des instants donnés et il est intéressant d’adapter l’offre à la demande. En d’autres termes il faut que le monitoring du système permette d’observer la charge en temps réel et d’ajouter ou retirer des instances dynamiquement en fonction de cette charge.
Maintenant, quelles sont les contraintes qui permettent de rendre un service responsive et elastic ?
Lors de la conception et du développement, il faut penser le service de façon à ce qu’il puisse scaler horizontalement. Il faut que ses multiples instances puissent se partager les requêtes successives d’un même client et y répondre de manière cohérente. Voici quelques pistes pour y arriver:
Premièrement il faut un load balancer. Un point d’entrée du système qui répartisse les requêtes sur tous les « back-ends », les instances disponibles.
L’utilisation d’une interface REST a par définition l’avantage d’être « stateless ». On peut externaliser l’état du système à une base de donnée, et éviter de garder un état en mémoire. De cette façon deux requêtes consécutives peuvent être traitées par des serveurs différents. La base de donnée elle-même devient un goulet, mais ce n’est plus la responsabilité du système et des solutions propres au bases de données existent pour scaler horizontalement: Réplication, Sharding.
L’authentification d’un utilisateur se fera à chaque requête. Par exemple à travers un token.
Si pour un projet front-end on est contraint de gérer une session utilisateur du côté serveur (p.ex login), on veillera a ce que celle-ci soit également sérialisée dans une base partagée. Le système doit répondre à toutes les requêtes dans un temps donné, éventuellement par une erreur. Attentions aux listes; elles devront être paginées.
On évitera d’attendre sur les opérations longues. Par exemple le batch processing: on préférera que le système implémente une queue, et que l’interface permette d’ajouter des éléments dans cette queue et de voir l’état de progression de l’opération. Ces opérations (ajout, et consultation de l’état) resteront rapides, même si le travail demandé au système prend du temps.
On évitera qu’un service bloque. Si quelque chose est imprévu, par exemple une connexion à la base de donnée perdue, on préférera que le système crashe et reprenne, plutôt qu’il réessaie et fasse attendre la requête.
On évitera que le service prenne des initiatives, par exemple qu’il soit doté d’un scheduler pour effectuer des tâches périodiques. Ou alors il faut mettre en place un mécanisme pour que deux instances puissent effectuer la même tâche au même moment sans qu’il y ait de conflit.
Un système doit également connaître ses limites. On préférera qu’il refuse une requête en cas de surcharge plutôt qu’il prenne trop de temps à la satisfaire.
Il n’est pas toujours bon d’être le plus rapide possible. Si on prend le cas de services qui partagent un bus d’événements, on peut vouloir ralentir la vitesse d’envoi de requête pour économiser un service, et réciproquement ralentir l’envoi de réponse. Le client évitera d’avoir plus de n requêtes en attente, il s’agit ici d’implémenter un système de « back pressure ».
L’élasticité du système dépend d’un bon outil de monitoring et d’un agent qui permettent de décider s’il faut ajouter ou supprimer des instances du système. Des solutions toutes prêtes sont disponibles chez les fournisseurs cloud. P.ex. Elasticbeanstalk chez AWS.
Le choix d’une ‘politique’ pour ajouter / supprimer des instances est assez délicat. Il faut prendre en compte :
- Le temps que met une instance à démarrer.
- La vitesse d’augmentation du rpm qu’on peut ou veut supporter, il s’agit de la dérivée de notre metric de base : les rpm.
- Le paramètre ou les paramètres à observer (CPU, network), en fonction de ce qui fait ralentir le système en premier.
Une approche exploratoire est souvent nécessaire pour configurer la politique ‘scale out / scale in’ d’un service. Des outils de load testing permettent de modéliser des scénarios proches de cas réels ; par exemple Gatling.
Load Testing avec un script Gatling
Cet outil open source permet de modéliser le comportement d’un client web (browser, connected device), d’augmenter progressivement une population – et par conséquent le nombre de rpm – afin d’observer comment le système réagit. Les requêtes sont envoyées de différents points du globe et on observe les temps de réponse du point de vue client.
Voici les résultats d’un load test obtenus à l’aide d’un script Gatling via la plateforme flood.io:
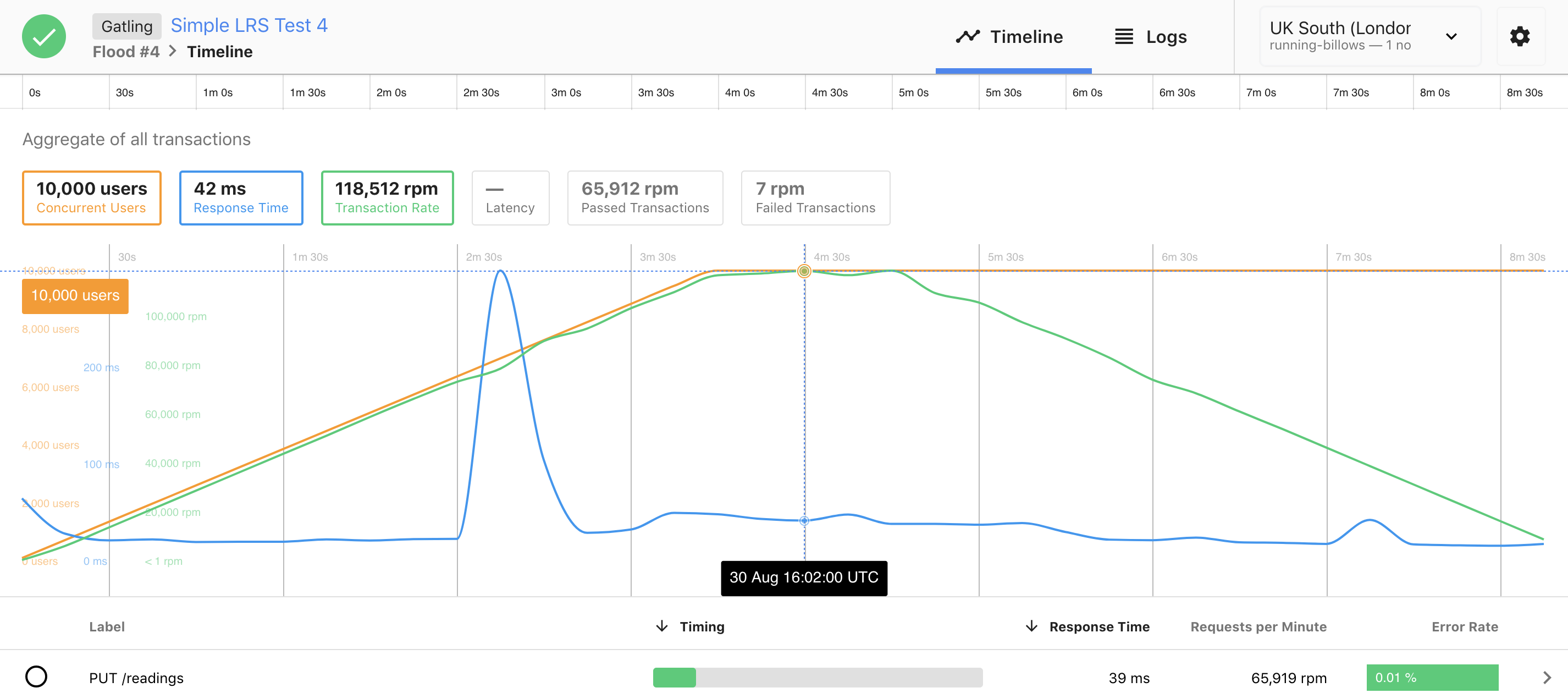
Dans ce scénario, on connecte progressivement 10’000 utilisateurs en 4 minutes (ligne orange), et on augmente ainsi le nombre de requêtes par minutes de 0 à 120’000 rpm (ligne verte).
On constate que le temps de réponse reste plus ou moins constant, aux alentours de 50 ms (ligne bleue). Le petit pic à 300ms correspond à un événement de scale out: l’apparition d’une ou plusieurs nouvelles instances.
Voici un autre exemple, où les choses se passent relativement mal :
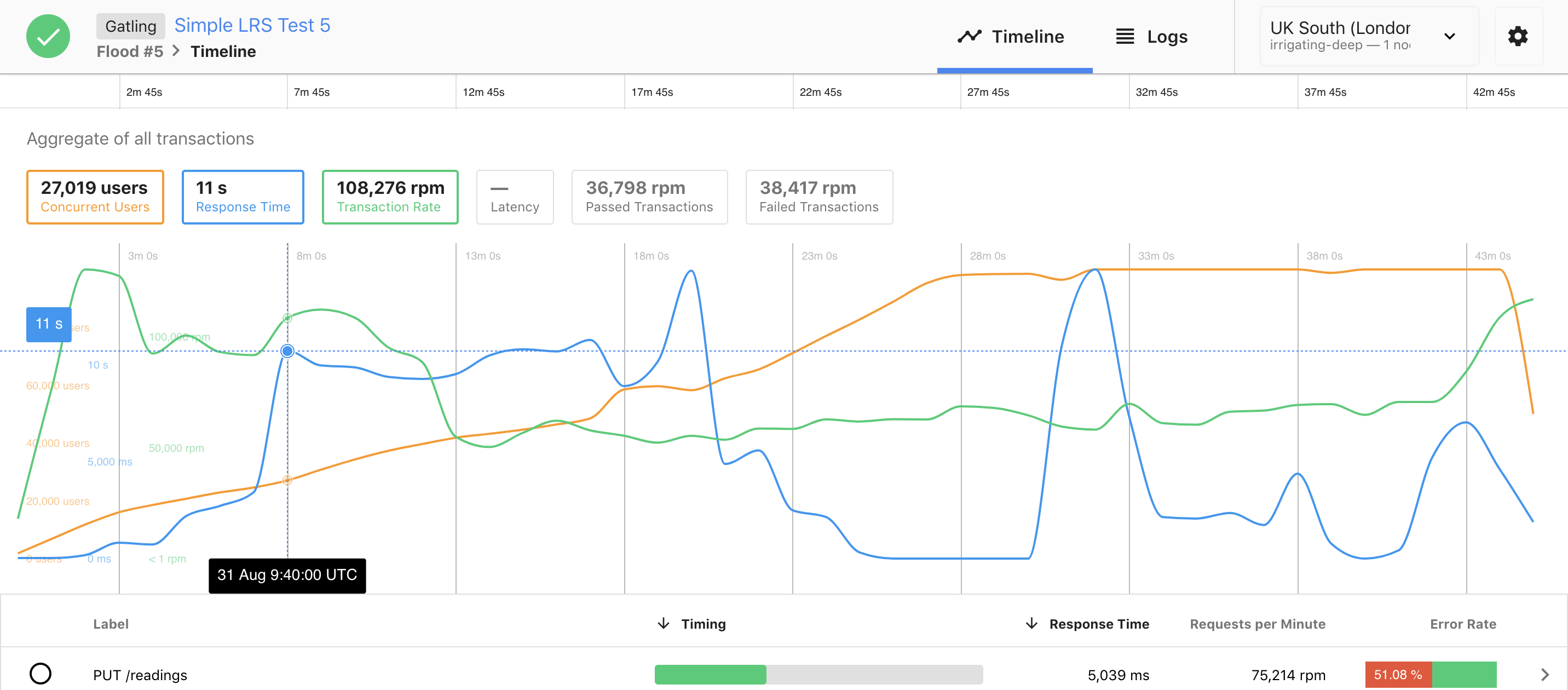
Dans ce scénario, la vitesse d’ajout de nouveaux utilisateurs est beaucoup trop rapide pour le système. En 90 secondes il y a déjà 10’000 utilisateurs, et le temps de réponse augmente jusqu’à 11 secondes par requêtes alors qu’il était stable pour la même charge dans l’exemple précédent. Le système devient et reste inutilisable durant toute la fin du test.
Il y a beaucoup à dire sur les tests de charge et leur interprétation. Ce sont des opérations relativement chronophages, mais il n’y a pas de meilleur moyen pour valider les capacités d’un système. De plus, quelque soit sa configuration et la qualité de son architecture, il y aura toujours une limite. Mieux vaut donc la connaître, et savoir ce qu’il se passe lorsque celle-ci est atteinte. Un système, même s’il devient inutilisable parce que surchargé, devrait pouvoir se rétablir lorsque la tempête est passée. Aussi, les inévitables erreurs qui apparaissent lorsqu’on atteint les limites ne doivent pas générer d’inconsistances dans les données, sans quoi c’est tout l’édifice qui s’effondre.



