
I have relatively often mentioned the “Reactive Manifesto” on different occasions at Apptitude. In discussions related to development or architectural choices, but also with non-technical people – both internal and external – to demonstrate that certain development choices can, and should, be governed by principles.
The fact is that a “manifesto” illustrates this concept well. Take artistic manifestos, such as Dogma 95 in Danish cinema – I always like to see that our profession has a lot of similarities with the artistic field – In short, whether we like “Les Idiots” or not, the cinematographic result was in accordance with the director’s intentions because he had set a number of measures and constraints during his shooting.
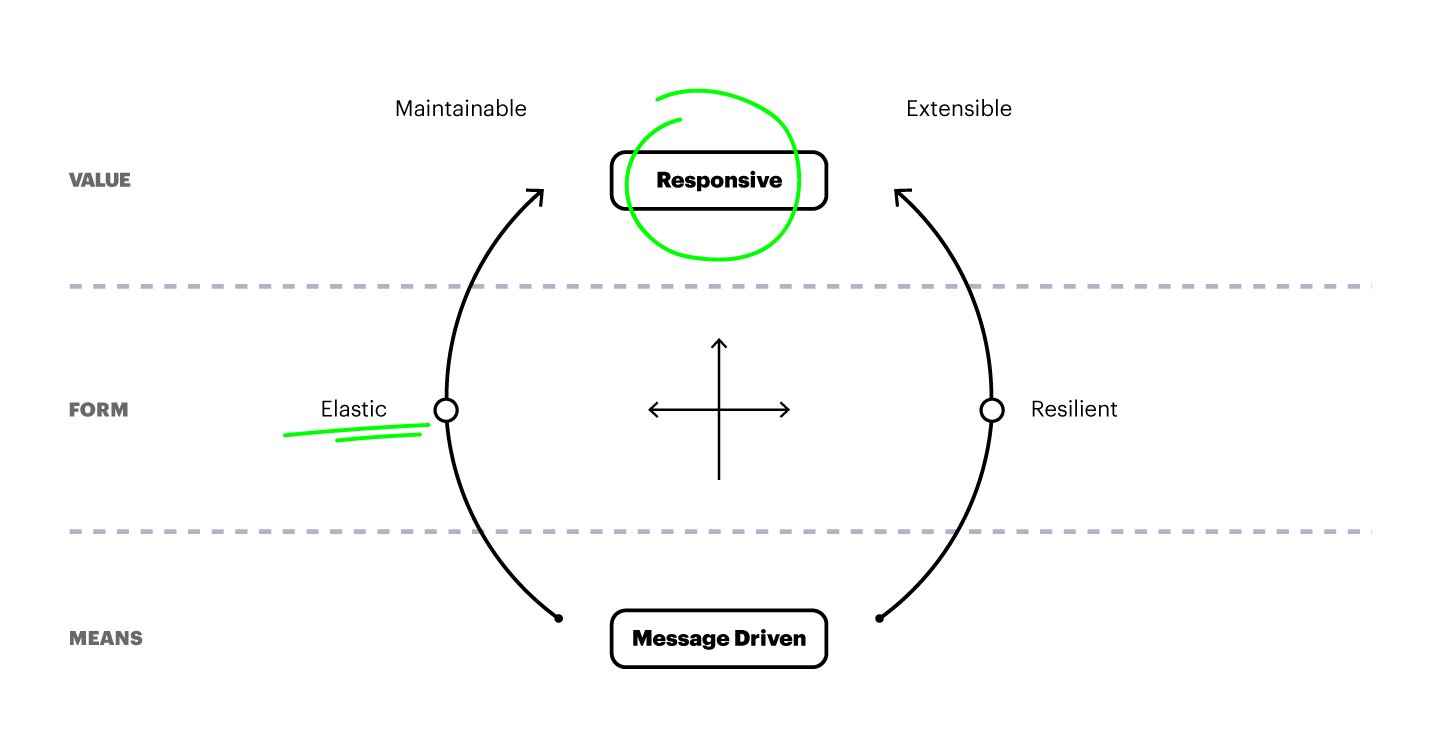
In the context of distributed system architecture, instead of discussing technical choices, the “Reactive Manifesto” defines a charter. A set of principles that, if followed, will contribute to a stable and robust system.
Responsive & Elastic
Let’s have a look at two keywords in the manifesto: “a system needs to be responsive” and “a system needs to be elastic”. These principles make sense in all kinds of distributed projects, such as web services. Let’s explore what we mean by these terms, what they entail and some ways to implement them.
Imagine a platform for booking guest rooms. Each of the actions you take is translated into a network request between your browser and a REST API, the back-end. Before you can see the result of your action (a search, a reservation,…) your browser will have to wait for the server answer. This waiting time is at the root of the “responsiveness” principle: whatever the circumstances, a system must respond to requests within a given timeframe. If it’s unable to process the request, for example, because it’s overloaded, it will probably have to answer with an error but also within a given time.
Why? Because it is otherwise impossible for the users to know if they have to keep waiting, or if they have to start again and this is incompatible with a satisfying user experience.
From the user’s point of view.
Mostly, a system itself is composed of subsystems, or “micro-services”. If one of these services cannot rely on a prompt response from the service processing its request, it will defer its expectation to its clients, degrading the overall performance of the system.
If we consider the system as a whole along with its user experience: we can assume that after a second of waiting between the action and the “feedback”, the user will perceive the system as dysfunctional…
What makes a service non-responsive?
Probably the load. In other words, the number of requests the system must process per minute (rpm). The more it increases, the more a system will be loaded and the longer it will need to respond.
Why does the load slow the system down?
Probably because a resource is saturated. Which one? Well, it depends on what the system has to do to respond to requests. This can be the I/O (network, disk) or the CPU. The solution to hold more load is to increase the capacity of the overloaded service (scale-up). There are two ways of scaling a system. Vertical scaling: we increase the capacities (more CPU, better network interface), or Horizontal scaling: we increase the number of instances of the service so that they share the load, i.e. incoming requests.
We can easily understand that the second solution is less limited than the first. Today, thanks to the “containerization” of services and cloud hosting, it’s possible to programmatically start a new instance of a service in a few seconds.
This leads us to the second keyword “elasticity”… If on the one hand the number of instances of a service is multiplied in order to respond to an increasing number of requests, the infrastructure costs of this system are also expected to increase. However, the “rpm” of a service is not stable. There may be peaks in demand at given times and it is interesting to match demand with supply. In other words, the system monitoring must watch the load in real-time and add or remove instances dynamically accordingly to this charge.
Now, what are the constraints that make it possible to provide a responsive and elastic service?
During design and development, the service should be conceived in such a way that it can be scaled horizontally. Its multiple instances have to be able to share successive requests from the same client and respond to them in a consistent manner. Here are some ways to get there:
First of all, you need a load balancer. A system entry point that distributes requests to all backends, available instances.
The use of a REST interface has the advantage of being « stateless ». The system state must be stored into a database so it’s shared among instances and not kept in memory. This way, two consecutive requests can be processed by different servers. The database itself becomes a bottleneck, but it is no longer the responsibility of the system and solutions exist to scale databases horizontally: Replication, Sharding.
User authentication will be done on each request. For example through a token.
If for a front-end project, you are required to store user session data on the server side (e. g. login), you must ensure that it is also serialized in a shared database.
The system must respond to all requests within a given time, possibly with an error. Be careful with the lists; they will have to be paginated.
Try to avoid lengthy waiting time on long operations. For example, batch processing: it is preferable that the system implements a queue, and that the interface allows to add elements in this queue and to visualize the progress status of the operation. These operations (adding and consulting the status) will remain fast, even if the work required from the system takes time.
Prevent a service from blocking. If something is unexpected, such as a connection to the lost database, one would prefer that the system crashes and resumes rather than try again and make the request wait.
It is important to prevent the service from taking initiatives, for example by having a scheduler perform periodic tasks. Alternatively, a mechanism should be put in place so that two instances can perform the same task at the same time without conflict.
A system must also be aware of its limitations. It is preferable that it rejects a request in case of overload rather than taking way too long to satisfy it.
It is not always advisable to be as fast-paced as possible. If we take the case of services that share an event “bus”, we may want to slow down the rate of request submission to protect a service, and conversely, slow down the response transmission. The client will then avoid having more than n requests pending, it is a way of implementing a “back pressure” system.
The elasticity of a system depends on a good monitoring tool and an agent to decide whether to add or remove instances of the system. Ready-made solutions are available from cloud providers, for example, Elasticbeanstalk by AWS.
The choice of a’policy’ to add/remove instances can be quite tricky. It is necessary to take into account:
- The time it takes for an instance to start.
- The speed of increase of the rpm that we can or want to support, it is the derivative of our basic metric: the rpm.
- The parameter or parameters to be watched (CPU, network), depending on what slows down the system first.
An exploratory approach is often necessary to configure the scale-out / scale-in policy of a service. Load testing tools allow to model scenarios close to real cases; for example Gatling.
Load Testing with a Gatling script
This open-source tool allows to model the behavior of a web client (browser, connected device), and to gradually increase a population of users – and therefore the number of rpm – in order to observe how the system reacts. Requests are sent from different parts of the world and response times are then observed from the customer’s point of view.
Here are the results of a load test obtained using a Gatling script via the flood.io platform:
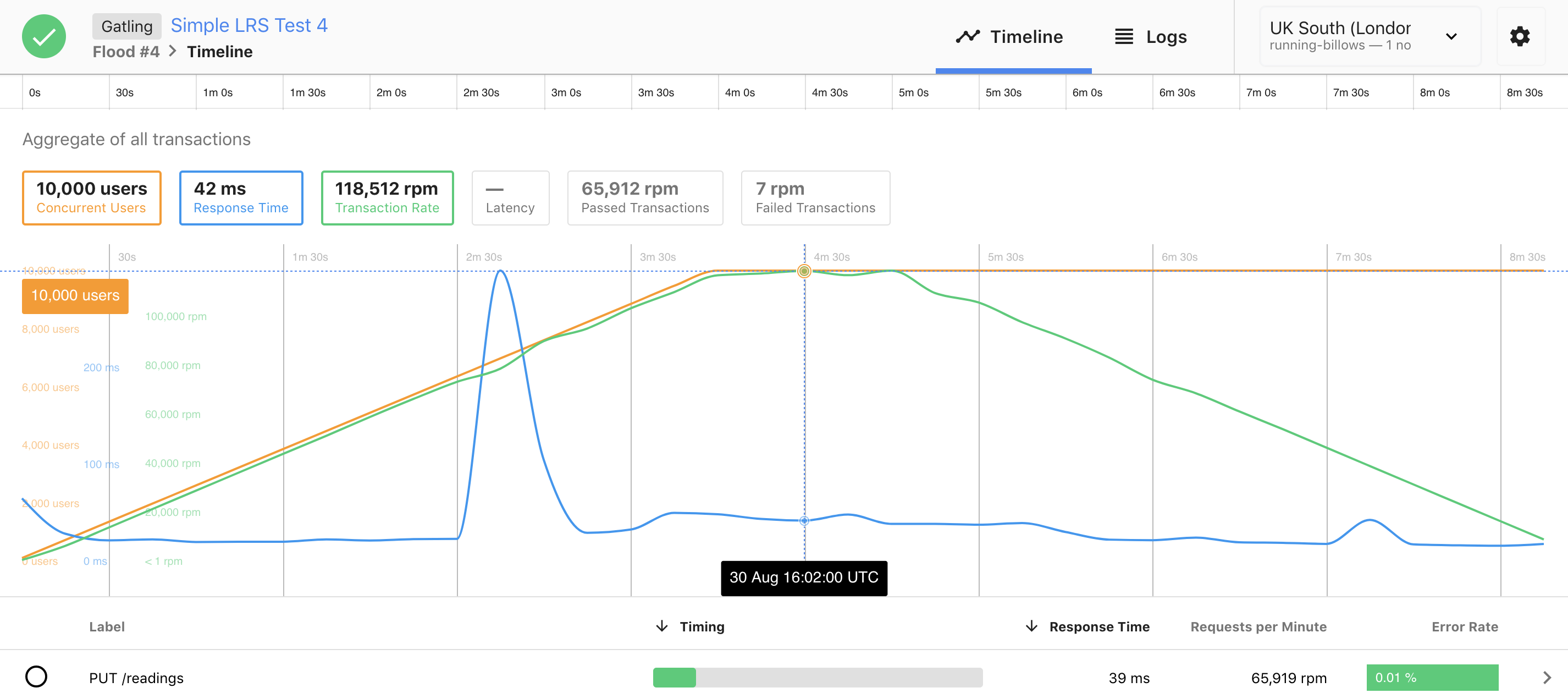
In this scenario, 10,000 users are gradually connected in 4 minutes (orange line), thus increasing the number of requests per minute from 0 to 120,000 rpm (green line).
It can be observed that the response time remains more or less constant, at around 50 ms (blue line). The small peak at 300ms corresponds to a scale-out event: the appearance of one or more new instances.
Here is another example, where things are going relatively wrong:
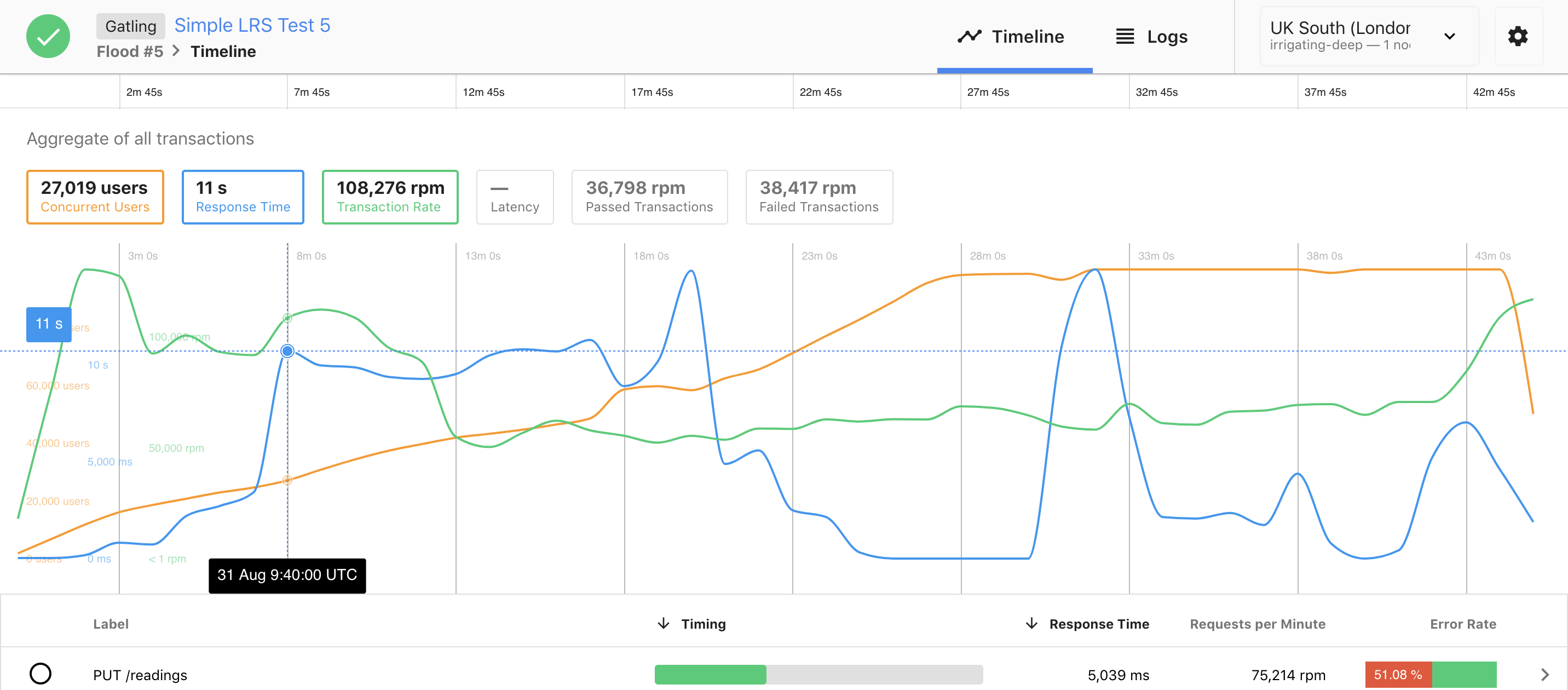
In this scenario, the rate at which new users are added is far too fast for the system. In 90 seconds there are already 10,000 users, and the response time increases to 11 seconds per request while it was stable for the same load in the previous example. The system becomes and remains unusable during the entire test period.
There is much to be said about load testing and its interpretation. These are relatively time-consuming operations, but there is no better way to validate a system’s capabilities. Moreover, whatever its configuration and the quality of its architecture, there will always be a limit. It is, therefore, better to know it and to know what happens when it is reached.
A system, even when it becomes unusable because it’s overloaded, should be able to recover after the storm has passed. Also, the inevitable errors that appear when the limits are reached must not generate inconsistencies in the data, otherwise the whole structure is set to collapse.



